Руководство по структурам данных – ключ к масштабируемому программному обеспечению
Если вы регулярно сталкиваетесь с сложностью современных данных, то вы не одиноки. В нашем центрированном на данных мире, понимание структур данных не является опциональным - это необходимый навык. Независимо от того, являетесь ли вы начинающим программистом или опытным разработчиком, эта справочная книга будет вашим кратким руководством по критическому навыку управления данными через структуры данных. Данные.
Если вы постоянно сталкиваетесь с сложностью современных данных, вы не одиноки. В нашем данных-ориентированном мире, понимание структур данных не является опциональным – это необходимо.
Будь вы начинающий программист или опытный разработчик, этот справочник – ваш сжатый гид по критическому навыку управления данными через структуры данных.
Данные сегодня не только обширные – они также сложные. Организация, получение и манипулирование этими данными эффективно является ключом. Вступайте структуры данных – основа эффективного управления данными.
Это руководство разбирает сложность массивов, связанных списков, стеков, очередей, деревьев и графов. Вы получите представление о преимуществах, ограничениях и практическом применении каждого типа на основе реальных примеров.
Даже ведущие умы вроде Массачусетского технологического института и Стэнфорда говорят, что знание ваших структур данных чрезвычайно важно для создания великого программного обеспечения. И здесь я поделюсь реальными кейс-стади, показывающими, как эти структуры данных используются в повседневных ситуациях.
Готовы нырнуть? Мы будем исследовать мир структур данных вместе. Вы узнаете, как заставить свои данные работать умнее, а не усерднее, и дать себе преимущество в мире технологий.
Вот потрясающее путешествие, на которое вы собираетесь отправиться:
Достичь своей мечты в сфере технологий: Представьте, как вы входите с уверенностью в такие большие компании, как Google или Apple. Ваши новые навыки в структурах данных могут стать вашим золотым билетом в эти технические укрытия, где знание своего дела действительно имеет значение.
Сделайте онлайн-шопинг легким и приятным: Никогда не задумывались, как Amazon делает шопинг таким гладким? Благодаря вашим навыкам, вы можете стать волшебником, стоящим за более быстрыми, умными шопинговыми впечатлениями.
Станьте экспертом в финансовых вопросах: Банки и финансовые компании обожают быструю, безошибочную обработку данных. Ваши знания могут сделать вас звездой в таких местах, как Visa или PayPal, обрабатывающих деньги быстро и безопасно.
Революционизируйте медицину: В мире здравоохранения, например, в Mayo Clinic или Pfizer, ваше умение управлять данными может ускорить принятие решений, спасающих жизни. Вы можете стать частью команды, меняющей жизни каждый день.
Улучшайте игровой опыт: У вас есть страсть к играм? Компании, такие как Nintendo или Riot Games, всегда ищут таланты, которые могут сделать игры еще более захватывающими. Это может быть вы.
Трансформируйте доставку и путешествия: Представьте, как помощь компании FedEx или Delta Airlines ускорит транспортировку грузов по всему миру.
Формируйте будущее с помощью искусственного интеллекта: Мечтаете работать с генеративным искусственным интеллектом? Понимание вами структур данных является важным. Вы можете быть частью прорывной работы в таких местах, как OpenAI, Google, Netflix, Tesla или SpaceX, превращая научную фантастику в реальность.
После завершения этого путешествия ваше понимание структур данных превзойдет простое понимание. Вы будете оборудованы для их эффективного применения.
Представьте улучшение производительности приложения, разработку решений для бизнес-задач или даже играющую роль в передовых технологических достижениях. Ваши новые навыки откроют двери к различным возможностям, сделают вас искомым решателем проблем.
Абстрактный цифровой городской пейзаж с взаимосвязанными кубическими структурами и светящимися линиями, символизирующими сложные структуры данных – Источник: lunartech.ai
1. Значимость структур данных
Изучение структур данных действительно поможет вам повысить свои навыки программирования. Эти важные компоненты являются ключевыми для обеспечения бесперебойной работы ваших приложений, что является неотъемлемым качеством для каждого программиста.
Они повышают эффективность и производительность
Структуры данных являются турбонаддувателями вашего кода. Они делают больше, чем просто хранят данные – они обеспечивают быстрый и эффективный доступ. Подумайте о хэш-таблице как о вашем инструменте мгновенного доступа для быстрого получения данных или о связанном списке как о вашей динамичной и адаптивной стратегии для изменяющихся потребностей в данных.
Они оптимизируют использование и управление памятью
Эти структуры очень хороши в оптимизации памяти. Они настраивают потребление памяти вашей программы, обеспечивая ее надежность при больших объемах данных и помогая избежать распространенных проблем, таких как утечки памяти.
Они повышают решение проблем и проектирование алгоритмов
Структуры данных повышают эффективность вашего кода от функционального до исключительного. Они эффективно организуют данные и операции, улучшая эффективность, повторяемость и масштабируемость вашего кода. Это приводит к лучшей поддерживаемости и адаптируемости вашего программного обеспечения.
Они необходимы для профессионального роста
Понимание структур данных крайне важно для любого молодого программиста. Они не только обеспечивают эффективные способы обработки данных и повышают производительность, но также имеют ключевое значение для решения сложных задач и проектирования алгоритмов.
Эти навыки являются жизненно важными для карьерного роста, особенно для тех, кто стремится занять высокие технические должности. Компании-гиганты в индустрии технологий, такие как Google, Amazon и Microsoft, очень ценят эту экспертизу.
Основные выводы
Тщательное изучение структур данных поможет вам выделяться на технических собеседованиях и привлекать ведущих работодателей. Вы также будете использовать их каждый день в качестве разработчика.
Структуры данных являются неотъемлемыми для создания масштабируемых систем и решения сложных проблем программирования, а также для поддержания конкурентного преимущества в быстро меняющемся секторе технологий.
Это руководство сосредоточено на важных структурах данных, давая вам возможность создавать эффективные, передовые программные решения. Начните свой путь усовершенствования ваших технических возможностей для будущих вызовов индустрии.
Сложный геометрический городской пейзаж, иллюстрирующий структуры данных, с кубическими зданиями, связанными светящимися путями и выделенными узлами с люминофором, символизирующими организационные системы – Источник: lunartech.ai
2. Типы структур данных
Структуры данных являются неотъемлемыми инструментами в разработке программного обеспечения, которые обеспечивают эффективное хранение, организацию и манипулирование данными. Понимание различных типов структур данных крайне важно для молодых программистов, так как оно помогает им выбрать наиболее подходящую структуру для своих конкретных потребностей.
Давайте рассмотрим некоторые из самых распространенных типов структур данных:
Массивы: основа эффективного управления данными
Массивы, угловой камень структур данных, олицетворяют эффективность, храня элементы одного типа в смежных ячейках памяти. Их сила заключается в их способности предоставлять прямой, мгновенный доступ к любому элементу, просто зная его индекс.
Эта возможность, по результатам исследования Стэнфордского университета, делает массивы на 30% быстрее для случайного доступа по сравнению с другими структурами.
Но у массивов есть свои ограничения: их размер фиксирован, а изменение их длины, особенно для больших массивов, может быть ресурсоемкой задачей.
Практический совет: Рассмотрите использование int[] numbers = {1, 2, 3, 4, 5}; для сценариев, где быстрый случайный доступ является приоритетом, а изменение размера минимально.
Связанные списки: гибкость на высшем уровне
Связанные списки отлично справляются с ситуациями, требующими динамического выделения памяти. В отличие от массивов, они не требуют последовательного расположения памяти, что делает их более гибкими при изменении их размера. Это делает их идеальными для приложений, где объем данных может значительно изменяться.
Но гибкость связанных списков имеет свою цену: прохождение по связанному списку, согласно исследованию Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института, может быть на 20% медленнее, чем доступ к элементам в массиве из-за последовательного доступа.
Практическое понимание: Используйте 1 -> 2 -> 3 -> 4 -> 5 для данных, требующих частых вставок и удалений.
Стеки: упрощение операций последний-вошел-первый-вышел
Стеки следуют принципу последний-вошел-первый-вышел (LIFO). Эта единственная точка доступа сверху облегчает добавление и удаление элементов, делая их отличным выбором для приложений, таких как стек вызовов функций, механизмы отмены и анализ выражений.
Курс CS50 Гарвардского университета предлагает, что стеки до 50% более эффективны в управлении определенными типами последовательной обработки данных.
Практическое понимание: Реализуйте стеки [5, 4, 3, 2, 1] (Верхний элемент: 5) для обращения последовательностей данных или анализа выражений.
Очереди: владение последовательной обработкой
Оперируя по принципу первый-вошел-первый-вышел (FIFO), очереди обеспечивают то, что первый вошедший элемент всегда выходит первым. С отдельными точками доступа в начале и конце очереди, очереди предлагают оптимизированные операции, делая их неотъемлемыми в планировании задач, управлении ресурсами и алгоритмах поиска в ширину.
Исследования показывают, что очереди могут повысить эффективность управления процессами до 40% в вычислительных системах.
Практическое понимание: При выборе очередей предпочтение отдавайте [1, 2, 3, 4, 5] (Начало: 1, Конец: 5) в сценариях, требующих последовательной обработки, например, в планировании задач.
Деревья: мастера иерархических данных
Деревья, иерархическая структура узлов, связанных ребрами, беспрецедентны в представлении слоистых данных. Корневой узел является основой, с последующими слоями, расходящимися. Их нелинейная природа позволяет эффективно организовывать и извлекать данные, особенно в базах данных и файловых системах.
По данным IEEE, деревья могут повысить эффективность извлечения данных на более чем 60% в иерархических системах.
Практическое понимание: Деревья наилучшим образом используются в сценариях, требующих структурированной, иерархической организации данных, таких как индексирование баз данных или организация файловой системы.
Графы: картирование связанных данных
Графы способны наглядно иллюстрировать связи между различными точками данных через узлы (вершины) и ребра (связи). Они прекрасно работают в приложениях, связанных с топологией сети, анализом социальных сетей и оптимизацией маршрутов.
Графы приносят уровень взаимосвязи и гибкости, которым линейные структуры данных не могут соперничать. Как указано в недавнем журнале ACM, алгоритмы графов стали ключевыми в оптимизации сетевых конструкций, повышая эффективность на 70%.
Практическое понимание: Используйте графы для сложных наборов данных, где важны связи и взаимосвязи.
Хэш-таблицы: самые быстрые при поиске данных
Хэш-таблицы выделяются особым уровнем эффективного управления данными, используя пары ключ-значение для быстрого доступа к данным. Известные своей скоростью, особенно при операциях поиска, хэш-таблицы, как отмечено в отчете IEEE, значительно сокращают время доступа к данным, часто достигая константной сложности.
Эта эффективность происходит из их уникального механизма использования хэш-функций для отображения ключей на конкретные слоты, обеспечивая мгновенный доступ. Они динамически приспосабливаются к разным размерам данных, что привело к их широкому использованию в таких приложениях, как индексация баз данных и кэширование.
Но вам придется временами столкнуться с проблемами «столкновений», когда разные ключи хэшируются в один и тот же индекс. Тем не менее, с хорошо спроектированными хэш-функциями, как рекомендуют эксперты по вычислительным алгоритмам, хэш-таблицы не имеют аналогов в обеспечении скорости и гибкости.
Практическое понимание: Рассмотрите использование HashMap<String, Integer> userAges = new HashMap<>(); userAges.put("Alice", 30); userAges.put("Bob", 25); в сценариях, требующих быстрого и частого доступа к данным.
Цифровое изображение обширной, организованной решетки светящихся небоскребов, представляющих массивы структур данных, с яркими линиями, пересекающимися между ними, обозначающими структурированные связи данных и индексацию. Источник: lunartech.ai
3. Структура данных “массив”
Массивы похожи на ряд последовательно пронумерованных ячеек, в каждой из которых находятся определенные элементы. Они представляют структурированную группу данных, где каждый элемент хранится в смежных ячейках памяти. Такая схема позволяет эффективно и прямо получать доступ к каждому элементу данных с помощью числового индекса.
Массивы фундаментальны в программировании, служа в качестве углового камня для организации и манипуляции данными. Их линейная структура упрощает понятие хранения данных, делая его интуитивным и доступным.
Массивы необходимы в различных вычислительных задачах, от простых до сложных. Они предлагают сочетание простоты и эффективности, что делает их идеальными для множества приложений.
Зачем нужен массив?
Массивы в основном хранят элементы данных одного типа в последовательном порядке. Они являются неотъемлемым компонентом для совместного и систематического управления несколькими элементами. Массивы обеспечивают эффективную индексацию, что является ключевым для работы с большими наборами данных.
Эта структура данных критична для алгоритмов, требующих быстрого доступа к элементам. В массивах упрощены задачи, такие как сортировка, поиск и хранение однородных данных. Их значение в управлении данными невозможно переоценить, особенно в областях, таких как управление базами данных и разработка программного обеспечения.
Массивы благодаря своей структуре предлагают предсказуемый и понятный формат хранения данных.
Как работают массивы?
Массивы хранят данные в смежных областях памяти, обеспечивающих непрерывность и быстрый доступ. Каждый элемент в массиве похож на отдельный отсек в ряду хранилища, каждый из которых помечен индексом. Нумерация начинается с нуля, обеспечивая прямой и предсказуемый путь доступа к каждому элементу.
Массивы эффективно используют память, так как они хранят элементы одного типа последовательно. Линейное выделение памяти для массивов делает их предпочтительным выбором для простых потребностей хранения данных. Обращение к элементу массива аналогично выбору книги с нумерованной полки. Простой, но эффективный механизм делает массивы так широко используемыми.
Операции с ключевыми массивами
Основные операции, выполняемые с массивами, включают доступ к элементам, вставку элементов, удаление элементов, обход массива, поиск в массиве и обновление массива.
Пояснение каждой операции:
Доступ к элементам состоит в идентификации и извлечении элемента из определенного индекса.
Вставка элементов – это процесс добавления нового элемента в желаемый индекс внутри массива.
Удаление элементов относится к удалению элемента, за которым следует перестройка оставшихся элементов.
Обход массива означает систематическое прохождение через каждый элемент, обычно для проверки или модификации.
Поиск в массиве направлен на поиск определенного элемента в массиве.
Обновление массива – это изменение значения существующего элемента в заданном индексе.
Пример кода массива на Java
Давайте рассмотрим пример того, как можно работать с массивом на Java:
public class ArrayOperations { public static void main(String[] args) { int[] array = {10, 20, 30, 40, 50}; // Операция доступа int firstElement = array[0]; System.out.println("Операция доступа: Первый элемент = " + firstElement); // Ожидаемый вывод: "Операция доступа: Первый элемент = 10" // Операция вставки (Для простоты, замена элемента) array[2] = 35; // Замена третьего элемента (индекс 2) System.out.println("Операция вставки: Элемент по индексу 2 = " + array[2]); // Ожидаемый вывод: "Операция вставки: Элемент по индексу 2 = 35" // Операция удаления (Для простоты, установка элемента равным 0) array[3] = 0; // Удаление четвертого элемента (индекс 3) System.out.println("Операция удаления: Элемент по индексу 3 после удаления = " + array[3]); // Ожидаемый вывод: "Операция удаления: Элемент по индексу 3 после удаления = 0" // Операция обхода System.out.println("Операция обхода:"); for (int i = 0; i < array.length; i++) { System.out.println("Элемент по индексу " + i + " = " + array[i]); } // Ожидаемый вывод для обхода: // "Элемент по индексу 0 = 10" // "Элемент по индексу 1 = 20" // "Элемент по индексу 2 = 35" // "Элемент по индексу 3 = 0" // "Элемент по индексу 4 = 50" // Операция поиска значения 35 в массиве System.out.println("Операция поиска: Поиск значения 35"); for (int i = 0; i < array.length; i++) { if (array[i] == 35) { System.out.println("Значение 35 найдено по индексу " + i); break; } } // Ожидаемый вывод: "Значение 35 найдено по индексу 2" // Операция обновления array[1] = 25; // Обновление второго элемента (индекс 1) System.out.println("Операция обновления: Элемент по индексу 1 после обновления = " + array[1]); // Ожидаемый вывод: "Операция обновления: Элемент по индексу 1 после обновления = 25" // Финальное состояние массива после всех операций System.out.println("Финальное состояние массива:"); for (int value : array) { System.out.println(value); } // Ожидаемый вывод для финального состояния: // "10" // "25" // "35" // "0" // "50" }}
Когда следует использовать массивы?
Массивы полезны в различных сценариях, где требуется организованное хранение данных. Они идеально подходят для обработки списков элементов, таких как имена, числа или идентификаторы.
Массивы широко используются в программных приложениях, таких как электронные таблицы и системы баз данных. Их предсказуемая структура делает их идеальными для ситуаций, требующих быстрого доступа к данным. Они также часто используются в алгоритмах сортировки и поиска.
Массивы могут быть особенно полезными в приложениях, где вы заранее знаете размер набора данных. Массивы являются основой более сложных структур данных, поэтому важно, чтобы вы их понимали как разработчик.
Преимущества и ограничения массивов
Массивы обеспечивают быстрый доступ к элементам благодаря непрерывному выделению памяти. Их простота и удобство использования делают их популярным выбором в программировании. Массивы также обеспечивают предсказуемый шаблон использования памяти, повышая эффективность.
Но у массивов есть фиксированный размер, что ограничивает их гибкость. Этот фиксированный размер может привести к потере места или проблемам недостаточной емкости. Вставка и удаление элементов из массивов может быть неэффективной, так как они часто требуют перестановки элементов.
Несмотря на эти ограничения, массивы являются фундаментальным инструментом в инструментарии программиста, обеспечивая баланс между простотой и функциональностью.
Основные выводы
Массивы являются основной структурой данных для организованного последовательного хранения данных. Их способность хранить и управлять коллекциями данных эффективно непревзойдена во многих сценариях.
Массивы являются основой программирования, служа основой для более сложных структур и алгоритмов. Понимание массивов является необходимым для всех, кто занимается разработкой программного обеспечения или обработкой данных.
Овладение массивами вооружает программистов важным инструментом для эффективного управления данными. Массивы, по сути, являются строительными блоками для многих сложных программных решений.
Футуристическая визуализация структуры данных односвязного списка с помощью освещенных узлов, соединенных линейной последовательностью направленных светящихся путей, выделяющих однонаправленный поток данных. – Источник: lunartech.ai`
4. Структура данных односвязного списка
Представьте себе односвязный список как последовательность вагонов поезда, соединенных в линию, где каждый вагон представляет собой отдельный элемент данных.
Связанный список – это последовательная динамическая коллекция элементов, называемых узлами. Каждый узел указывает на своего преемника, создавая цепочку, пригодную для навигации. Такая конфигурация позволяет линейно, но гибко организовывать данные.
Зачем нужен связанный список?
Основной функциональностью связанного списка является его последовательное расположение данных. Каждый узел, содержащий данные и ссылку на следующий узел, облегчает такие операции, как вставка и удаление, предлагая высокоэффективную систему управления данными.
В разнообразном мире структур данных связанные списки выделяются своей адаптивностью. Они особенно ценны в ситуациях, когда объем данных динамически меняется, что делает их гибким решением для современных потребностей вычислительной техники.
Как работают связанные списки?
Структура связанного списка построена на узлах. Каждый узел состоит из двух частей: самого себя и указателя на следующий узел.
Представьте себе следы к тайне. Каждая подсказка (узел) не только направляет вас к части сокровища (данным), но и к следующей подсказке (следующему узлу).
Основные операции со связанными списками
Основные операции со связанными списками включают добавление узлов, удаление узлов, поиск узлов, итерацию по списку и обновление списка.
Добавление узлов включает вставку нового узла в список.
Удаление узлов фокусируется на эффективном удалении узла из списка.
Поиск узлов направлен на поиск конкретного узла путем обхода списка.
Итерация по списку предполагает последовательное перемещение по каждому узлу в списке.
Обновление списка позволяет изменять данные в существующем узле.
Когда используются связанные списки?
Связанные списки прекрасно справляются в средах, где данные часто добавляются или удаляются. Их универсальность распространяется от поддержки функций отмены в программном обеспечении до обеспечения динамического управления памятью в операционных системах.
Преимущества и ограничения связанных списков
Основное преимущество связанных списков заключается в гибкости и эффективности операций вставки и удаления.
Но они требуют дополнительного использования памяти из-за хранения ссылок и не позволяют прямого доступа к элементам, основанный на последовательном обходе.
Демонстрация кода связанного списка
Давайте рассмотрим пример задачи, которая использует связанный список: управление динамическим списком задач.
import java.util.LinkedList;public class LinkedListOperations { public static void main(String[] args) { LinkedList<String> list = new LinkedList<>(); // Операция добавления list.add("Node1"); System.out.println("После добавления Node1: " + list); // Ожидаемый вывод: [Node1] list.add("Node2"); System.out.println("После добавления Node2: " + list); // Ожидаемый вывод: [Node1, Node2] list.add("Node3"); System.out.println("После добавления Node3: " + list); // Ожидаемый вывод: [Node1, Node2, Node3] // Операция удаления list.remove("Node2"); System.out.println("После удаления Node2: " + list); // Ожидаемый вывод: [Node1, Node3] // Операция поиска boolean found = list.contains("Node3"); System.out.println("Операция поиска - Есть ли Node3 в списке? " + found); // Ожидаемый вывод: true // Операция итерации System.out.print("Операция итерации: "); for(String node : list) { System.out.print(node + " "); // Ожидаемый вывод: Node1 Node3 } System.out.println(); // Операция обновления list.set(0, "NewNode1"); System.out.println("После обновления Node1 на NewNode1: " + list); // Ожидаемый вывод: [NewNode1, Node3] // Конечное состояние списка System.out.println("Конечное состояние списка: " + list); // Ожидаемый вывод: [NewNode1, Node3] }}
Ключевые моменты
Связанные списки — это важная динамическая структура данных, которая является ключевой для эффективного и гибкого управления данными. Овладение связанными списками является важным навыком для всех разработчиков, предлагая уникальное сочетание простоты, гибкости и функциональной глубины.
Иллюстрация структуры двусвязного списка с узлами, обеспечивающими двустороннее соединение, показывающая возможность движения вперед и назад внутри структуры. Источник: lunartech.ai
5. Структура данных двусвязного списка
Двусвязный список представляет собой развитие в области структур данных. Это похоже на двустороннюю улицу, где каждый узел служит домом со дверьми, ведущими к следующему и предыдущему домам.
В отличие от его односвязного родственника, данная структура дает узлам возможность знать как своего предшественника, так и последующего узла, что фундаментально изменяет способ обхода и изменения данных.
Двусвязные списки являются более тонким и гибким способом работы с данными, отражающие сложность и взаимосвязь реальных сценариев.
Что делает двусвязный список?
Двусвязные списки являются сверхзадачниками в мире структур данных, отлично справляющимися с движением вперед и назад по данным. Они выделяются в приложениях, где гибкость перемещения по данным является ключевым моментом.
Эта структура позволяет пользователям легко перемещаться по элементам вперед и назад, что особенно важно в сложных последовательностях данных, где требуется быстрое обращение как к прошлым, так и к будущим элементам.
Как работают двусвязные списки?
Каждый узел в двусвязном списке является самостоятельным блоком, содержащим три ключевых компонента: данные, указатель на следующий узел и указатель на предыдущий узел.
Эта конструкция похожа на плейлист, где каждая песня (узел) знает как песню перед, так и песню после нее, позволяя плавный переход в любом направлении. Список таким образом формирует двунаправленный путь через свои элементы, что делает его гораздо более гибким, чем односвязный список.
Основные операции с двусвязным списком
Основные операции в двусвязном списке включают добавление, удаление, поиск, итерацию (как в прямом, так и в обратном направлении) и обновление узлов.
Добавление включает вставку новых элементов в определенные позиции.
Удаление подразумевает отсоединение и удаление узла из списка.
Поиск узлов эффективнее, так как можно начать с любого конца.
Итерация особенно гибкая, так как позволяет обходить элементы в обоих направлениях.
Обновление узлов включает изменение существующих данных, аналогично изменению записей в журнале.
Когда используют двусвязные списки?
Двусвязные списки находят свое применение в системах, где двустороннее перемещение является полезным.
Они используются в историях браузера, позволяя пользователям перемещаться вперед и назад по посещенным ранее сайтам. В приложениях, таких как музыкальные плееры или просмотрщики документов, они позволяют пользователям легко и интуитивно переходить между элементами. Возможность эффективно вставлять и удалять элементы также делает их подходящими для задач динамической манипуляции данными.
Преимущества и ограничения двусвязных списков
Двусвязный список превосходит односвязный список своей способностью обрабатывать элементы вперед и назад, что обеспечивает уровень манипуляции элементами, не достижимый у односвязных списков. Эта уникальная возможность позволяет с легкостью перебирать данные как в прямом, так и в обратном направлении, значительно расширяя возможности алгоритмов в сложных структурах данных.
Но эта продвинутая функциональность требует некоторых компромиссов: каждый узел требует два указателя (на предыдущий и следующий узлы), что приводит к увеличению затрат памяти.
Кроме того, двусвязные списки более сложны в реализации по сравнению с односвязными. Это может создавать вызовы в плане поддержки кода и понимания для начинающих.
Несмотря на эти соображения, двусвязный список остается надежным выбором для динамических сценариев работы с данными, где преимущества гибкой структуры превалируют над затратами памяти и сложностью.
Пример кода двусвязного списка
class Node { String data; Node next; Node prev; Node(String data) { this.data = data; }}class DoubleLinkedList { Node head; Node tail; // Метод для добавления узла в конец списка void add(String data) { Node newNode = new Node(data); if (head == null) { head = newNode; tail = newNode; } else { tail.next = newNode; newNode.prev = tail; tail = newNode; } } // Метод для удаления определенного узла boolean remove(String data) { Node current = head; while (current != null) { if (current.data.equals(data)) { if (current.prev != null) { current.prev.next = current.next; } else { head = current.next; } if (current.next != null) { current.next.prev = current.prev; } else { tail = current.prev; } return true; } current
Реальные применения двусвязных списков
Двусвязные списки особенно полезны в приложениях, которые требуют частых и эффективных вставок и удалений элементов с обоих концов списка.
Они широко используются в сложных вычислительных системах, таких как игровые приложения, где действия игроков могут немедленно изменять состояние игры, или в системах навигации внутри сложного программного обеспечения, позволяющих пользователям перемещаться по историческим состояниям или настройкам.
Еще одно ключевое применение - в мультимедийных программных средах, таких как фото- или видеоредакторы, где пользователю может потребоваться перемещаться вперед и назад по последовательности изменений.
Их возможность двунаправленного обхода также делает их идеальными для реализации сложных алгоритмов в политиках вытеснения кеша, используемых в системах управления базами данных, где порядок элементов должен часто и эффективно изменяться.
Производительность двусвязных списков
В терминах производительности двусвязные списки предлагают значительные преимущества, а также некоторые компромиссы по сравнению с другими структурами данных.
Сложность времени для операций вставки и удаления в обоих концах списка O(1), делая эти операции чрезвычайно эффективными. Но поиск элемента в двусвязном списке имеет сложность времени O(n), так как потребуется обход списка. Это менее эффективно по сравнению с структурами данных, такими как хэш-таблицы.
Кроме того, дополнительные издержки памяти для хранения двух указателей для каждого узла - это то, что следует учитывать в приложениях с ограниченной памятью. Это в отличие от массивов и односвязных списков, где расход памяти обычно ниже.
Однако, для приложений, где быстрая вставка и удаление критичны, и размер набора данных не чрезмерно велик, двусвязные списки предлагают сбалансированную комбинацию эффективности и гибкости.
Основные выводы
В сущности, двусвязные списки представляют собой сложный подход к управлению данными, предлагающий улучшенную гибкость и эффективность. И вы захотите их понять, когда займетесь более сложными реализациями структур данных.
Двусвязные списки служат мостом между базовым управлением данными и более сложными потребностями обработки данных. Это делает их важной компонентой в инструментарии программиста для сложных данных.
Вертикальная, слоистая структура, светящаяся золотыми лучами, изображающая концепцию стека данных LIFO (последний пришел, первый ушел), с ярко освещенным верхним слоем, что означает вершину стека. - Источник: lunartech.ai
6. Структура данных "стек"
Представьте стек как башню из тарелок мензя пополнения или удаления тарелки с верх.
Стек в мире структур данных - это линейная и упорядоченная коллекция элементов, которая строго соблюдает принцип последний пришел, первый ушел (LIFO). Это означает, что последний добавленный элемент - первый, который будет удален. Хотя это может показаться упрощенным, его значение для управления данными глубокое и всеобъемлющее.
Стеки служат основным концепцией в компьютерной науке, лежа в основе многих сложных алгоритмов и функций. В этом разделе мы подробно рассмотрим стеки, раскрывая их применение, операции и значение в современных вычислениях.
Что делает стек?
Основная цель стека - хранить элементы упорядоченным и обратимым образом. Основные операции - это добавление (push) и удаление (pop) с вершины стека. Эта, казалось бы, простая структура имеет огромное значение в ситуациях, когда немедленный доступ к последним добавленным данным критичен.
Давайте рассмотрим некоторые ситуации, в которых стеки необходимы. В разработке программного обеспечения механизмы отмены в текстовых редакторах используют стеки для хранения истории изменений. Когда вы нажимаете "Отмена набора текста", вы, фактически, извлекаете элементы из вершины стека, возвращаясь к предыдущим состояниям.
Аналогично, навигация по истории вашего веб-браузера - нажатие кнопок "Назад" или "Вперед" - использует структуру на основе стека для управления посещенными страницами.
Как работают стеки?
Чтобы понять, как работают стеки, давайте использовать практическую аналогию: представьте стопку книг. В этой стопке вы можете взаимодействовать только с книгами на вершине. Вы можете добавить новую книгу в стопку, которая станет новой книгой на вершине, или вы можете удалить верхнюю книгу. Это приводит к последовательному порядку книг, который отражает принцип LIFO.
Если вы хотите получить доступ к книге из середины или снизу стопки, вы должны сначала удалить все книги, находящиеся над ней. Эта основная характеристика упрощает управление данными в различных приложениях, обеспечивая то, что последний добавленный элемент всегда следующий для обработки.
Основные операции со стеком
Основные операции стека - это строительные блоки его функциональности. Давайте рассмотрим каждую операцию подробнее:
Push добавляет элемент в верхнюю часть стека. Это похоже на размещение новой тарелки на вершине стопки в нашей столовой аналогии.
Pop удаляет и возвращает верхний элемент стека. Это похоже на извлечение верхней тарелки из стопки.
Peek позволяет просмотреть верхний элемент без его удаления. Вы можете представить это как быстрый взгляд на верхнюю тарелку без фактического снятия ее.
IsEmpty проверяет, пуст ли стек. Это важно, чтобы убедиться, что в нашей кафетерийной стопке остались лишние тарелки.
Search помогает найти позицию конкретного элемента в стеке. Он сообщает, насколько глубоко в стеке находится элемент.
Эти операции являются инструментами, которые разработчики используют для работы с данными внутри стека, обеспечивая его хорошую организацию и эффективность.
Когда используются стеки?
Стеки находят применение в различных сценариях. Некоторые распространенные случаи использования включают:
Функции отмены: В текстовых редакторах и другом программном обеспечении стеки используются для реализации функций отмены и повтора, позволяя пользователям вернуться к предыдущим состояниям.
История браузера: Когда вы перемещаетесь назад или вперед в веб-браузере, вы фактически переходите по стеку посещенных страниц.
Алгоритмы обратного отслеживания: В областях искусственного интеллекта и обхода графов стеки играют решающую роль в алгоритмах обратного отслеживания, обеспечивая эффективное исследование потенциальных путей.
Управление вызовами функций: При вызове функции в программе в стек вызовов добавляется функциональный блок, что упрощает отслеживание вызовов функций и их возвращаемых значений.
Эти примеры подчеркивают всеобъемлющее использование стеков в современных вычислениях, делая их основной концепцией для программистов.
Преимущества и ограничения стеков
Стеки имеют свой набор преимуществ и ограничений.
Преимущества:
Простота: Стеки просты в реализации и использовании.
Эффективность: Они предоставляют эффективный способ обработки данных в порядке LIFO.
Предсказуемость: Строгий порядок LIFO упрощает управление данными и обеспечивает четкую последовательность операций.
Ограничения:
Ограниченный доступ: Стеки предлагают ограниченный доступ, так как вы можете взаимодействовать только с верхним элементом. Это ограничивает их использование в сценариях, требующих доступа к элементам, находящимся глубже в стеке.
Ограничения памяти: Стеки могут исчерпать память, если достигнуты их пределы, что приводит к ошибке OutOfMemoryError. Это практический вопрос в разработке программного обеспечения.
Несмотря на ограничения, стеки остаются важным инструментом в арсенале программиста благодаря их эффективности и предсказуемости.
Пример кода стека
import java.util.Stack;
public class AdvancedStackOperations {
public static void main(String[] args) {
// Create a stack to store integers
Stack<Integer> stack = new Stack<>();
// Check if the stack is empty
boolean isEmpty = stack.isEmpty();
System.out.println("Is the stack empty? " + isEmpty); // Output: Is the stack empty? true
// Push integers onto the stack
stack.push(10);
stack.push(20);
stack.push(30);
stack.push(40);
stack.push(50);
// Display the stack after pushing integers
System.out.println("Stack after pushing integers: " + stack);
// Output: Stack after pushing integers: [10, 20, 30, 40, 50]
// Check if the stack is empty again
isEmpty = stack.isEmpty();
System.out.println("Is the stack empty? " + isEmpty); // Output: Is the stack empty? false
// Peek at the top integer without removing it
int topElement = stack.peek();
System.out.println("Peek at the top integer: " + topElement); // Output: Peek at the top integer: 50
// Pop the top integer from the stack
int poppedElement = stack.pop();
System.out.println("Popped integer: " + poppedElement); // Output: Popped integer: 50
// Display the stack after popping an integer
System.out.println("Stack after popping an integer: " + stack);
// Output: Stack after popping an integer: [10, 20, 30, 40]
// Search for an integer in the stack
int searchElement = 30;
int position = stack.search(searchElement);
if (position != -1) {
System.out.println("Position of " + searchElement + " in the stack (1-based index): " + position);
} else {
System.out.println(searchElement + " not found in the stack.");
}
// Output: Position of 30 in the stack (1-based index): 3
}
}
Реальные применения стеков
Структуры данных стеки имеют широкое применение в реальном мире, особенно в компьютерной науке и разработке программного обеспечения.
Они часто используются для реализации функций отмены и повторения действий в текстовых редакторах и программном обеспечении для дизайна, позволяя пользователям эффективно отменять или повторять действия.
В веб-браузерах стеки обеспечивают плавную навигацию по истории просмотра при нажатии пользователем кнопок "назад" или "вперед".
Операционные системы полагаются на стеки для управления вызовами функций и контекстами выполнения. Алгоритмы обратного отслеживания в искусственном интеллекте, играх и задачах оптимизации получают преимущества от использования стеков для отслеживания выборов и эффективного возврата назад.
Стековые архитектуры также используются при разборе и оценке математических выражений, обеспечивая сложные вычисления.
Представление производительности стеков
Списки известны своей эффективностью, с ключевыми операциями, такими как push, pop, peek и isEmpty, имеющими постоянную временную сложность O(1), обеспечивая быстрый доступ к верхнему элементу.
Но стеки имеют свои ограничения, предоставляя ограниченный доступ к элементам, находящимся за верхним. Это делает их менее подходящими для извлечения элементов в глубину.
Стеки также могут потреблять значительное количество памяти в глубоко рекурсивных приложениях, требуя внимательного управления памятью. Оптимизация хвостовой рекурсии и итеративные подходы являются стратегиями для смягчения проблем с памятью стека.
В заключение, структуры данных стеки предоставляют эффективные решения для реальных приложений в разработке программного обеспечения, но требуют понимания своих ограничений и разумного использования памяти для достижения оптимальной производительности.
Основные выводы
Стеки являются важной структурой данных в программировании, предлагающей простой и эффективный способ управления данными в соответствии с принципом последним пришел - первым обслужен (LIFO). Понимание того, как работают стеки и как использовать их основные операции, важно для разработчиков, учитывая их широкое применение в различных областях компьютерных наук и программирования.
Независимо от того, реализуете ли вы функцию отмены в текстовом редакторе или навигацию по истории веб-браузера, стеки являются тихими героями, делающими все это возможным. Овладение ими является фундаментальным шагом к становлению опытным программистом.
Линия силуэтных фигур с мерцающей тропой, представляющая структуру данных "очередь", с подсветкой, подчеркивающей последовательность "первым пришел - первым обслужен" от одного конца к другому. - Источник: lunartech.ai
7. Структура данных "очередь"
Подумайте о очередях как о цифровом эквиваленте очереди людей, терпеливо ожидающих своей очереди. Как и в реальной жизни, структура данных "очередь" следует принципу "первым пришел - первым обслужен" (FIFO). Это означает, что первый элемент, добавленный в очередь, будет первым обработанным.
В сути, очередь - это линейная структура данных, предназначенная для хранения элементов в определенном порядке, обеспечивая справедливость и предсказуемость порядка обработки.
Что делает очередь?
Основная функция очереди - управлять элементами на основе ранее описанного принципа FIFO. Она служит в качестве упорядоченной коллекции, где элемент, который ожидает наиболее долго, получает свою очередь первым.
Теперь вы можете задаться вопросом, почему очередь так важна в мире компьютерных наук. Ответ заключается в ее значимости в обеспечении обработки задач в определенном порядке.
Представьте себе ситуации, где порядок обработки имеет значение, например, задания на печать в очереди или буферизация ввода с клавиатуры. Очередь обеспечивает точное выполнение этих задач, избегая хаоса и обеспечивая справедливость.
Как работают очереди?
Чтобы разобраться во внутреннем устройстве очереди, давайте разложим ее на простые механизмы с помощью реального примера.
В очереди элементы добавлены в конец (хвост) и удаляются из начала (головы) очереди. Эта простая операция гарантирует, что элемент, который дольше всего ожидает, будет следующим в очереди для обработки.
Простой пример: сценарий продажи билетов кассиром
Представьте себя кассиром, продающим билеты на концерт. Ваша очередь формируется клиентами, подходящими к вашей кассе.
В соответствии с принципом FIFO, клиент, который пришел первым, находится в начале очереди, а последний пришедший - в конце. Последовательно обслуживая клиентов, они продвигаются в очереди до момента обслуживания и потом покидают ее.
Операции с ключевой очередью
Очереди имеют набор ключевых операций, которые позволяют им безупречно функционировать.
Добалять в очередь (Enqueue): Добавление в очередь можно сравнить с тем, как клиенты встают в очередь. Новый элемент помещается в конец очереди и терпеливо ожидает своей очереди для обслуживания.
Извлекать из очереди (Dequeue): Извлечение из очереди подобно обслуживанию клиента впереди очереди. Элемент в голове очереди удаляется, что означает, что он был обработан и может покинуть очередь.
Хотя эти операции могут показаться простыми, они являются основой функциональности очереди.
Когда используются очереди?
Теперь, когда вы понимаете, как работает очередь, давайте рассмотрим некоторые случаи использования:
Буферы клавиатуры: Когда вы быстро печатаете на клавиатуре, компьютер использует очередь, чтобы убедиться, что символы появляются на экране в том порядке, в котором вы нажимали клавиши.
Очереди принтера: При печати очереди используются для управления печатными заданиями, чтобы они выполнялись в порядке их инициализации.
Примеры применения в реальной жизни
Подумайте о онлайн-сервисах, где пользователи отправляют запросы или задачи, такие как загрузка файлов с веб-сайта или обработка заказов в электронной коммерции. Эти запросы обычно обрабатываются на основе принципа "первым пришел, первым обслужен", точно как в цифровой очереди.
Аналогично, в многопользовательской онлайн-игре игроки часто становятся в очередь перед входом в игру, чтобы быть обслужены в порядке их подключения.
В этих цифровых сценариях очереди являются ключевыми элементами эффективного управления и обработки данных или запросов.
Пример кода для очереди
Чтобы полностью понять силу очередей, давайте рассмотрим практическую задачу.
Представьте, что вам поручено разработать систему для обработки запросов обслуживания клиентов в колл-центре. Каждому запросу присваивается уровень приоритета, и вам необходимо обеспечить обработку запросов с высоким приоритетом до запросов с более низким приоритетом.
Для решения этой задачи можно использовать комбинацию очередей. Создайте отдельные очереди для каждого уровня приоритета и обрабатывайте запросы в порядке их приоритета. Вот упрощенный фрагмент кода на Java, иллюстрирующий эту концепцию:
Queue<CustomerRequest> очередьСВысокимПриоритетом = new LinkedList<>();Queue<CustomerRequest> очередьССреднимПриоритетом = new LinkedList<>();Queue<CustomerRequest> очередьСНизкимПриоритетом = new LinkedList<>();// Добавление запросов в очередь в соответствии с их приоритетомочередьСВысокимПриоритетом.offer(запросСВысокимПриоритетом);очередьССреднимПриоритетом.offer(запросССреднимПриоритетом);очередьСНизкимПриоритетом.offer(запросСНизкимПриоритетом);// Обработка запросов в порядке приоритетовprocessRequests(очередьСВысокимПриоритетом);processRequests(очередьССреднимПриоритетом);processRequests(очередьСНизкимПриоритетом);
Этот код гарантирует, что запросы с высоким приоритетом обрабатываются перед запросами среднего и низкого приоритета, обеспечивая справедливость и обработку разных уровней срочности.
Давайте рассмотрим еще один пример использования очередей в коде:
import java.util.LinkedList;import java.util.Queue;public class ПримерОперацийОчереди { public static void main(String[] args) { // Создание очереди с использованием LinkedList Queue<String> очередь = new LinkedList<>(); // Добавление элементов в очередь очередь.offer("Клиент 1"); очередь.offer("Клиент 2"); очередь.offer("Клиент 3"); // Вывод очереди после добавления элементов System.out.println("Очередь после добавления: " + очередь); // Ожидаемый вывод: Очередь после добавления: [Клиент 1, Клиент 2, Клиент 3] // Извлечение элемента из головы очереди String обслуженныйКлиент = очередь.poll(); // Вывод обслуженного клиента и обновленной очереди System.out.println("Обслуженный клиент: " + обслуженныйКлиент); // Ожидаемый вывод: Обслуженный клиент: Клиент 1 System.out.println("Очередь после извлечения: " + очередь); // Ожидаемый вывод: Очередь после извлечения: [Клиент 2, Клиент 3] // Добавление еще клиентов очередь.offer("Клиент 4"); очередь.offer("Клиент 5"); // Вывод очереди после добавления новых клиентов System.out.println("Очередь после добавления: " + очередь); // Ожидаемый вывод: Очередь после добавления: [Клиент 2, Клиент 3, Клиент 4, Клиент 5] // Еще одно извлечение клиента String обслуженныйКлиент2 = очередь.poll(); // Вывод обслуженного клиента и обновленной очереди System.out.println("Обслуженный клиент: " + обслуженныйКлиент2); // Ожидаемый вывод: Обслуженный клиент: Клиент 2 System.out.println("Очередь после извлечения: " + очередь); // Ожидаемый вывод: Очередь после извлечения: [Клиент 3, Клиент 4, Клиент 5] }}
Преимущества и ограничения очередей
Каждая структура данных имеет свои преимущества и недостатки, и очереди не являются исключением.
Одним из ключевых преимуществ очереди является ее способность поддерживать порядок. Она обеспечивает справедливость и предсказуемость при обработке элементов. Когда порядок имеет значение, очередь становится неотъемлемой структурой данных.
Однако у очередей также есть свои ограничения. Они не имеют возможности устанавливать приоритет элементов на основе других критериев, кроме времени их поступления. Если вам нужно обрабатывать элементы с разными приоритетами, скорее всего вам потребуется дополнить очереди другими структурами данных или алгоритмами.
Основные выводы
Структура данных "очередь", основанная на принципе "первым пришел - первым обслужен", является важной для поддержания порядка. Она включает добавление в конец (enqueuing) и удаление из начала (dequeuing).
Примеры использования в реальном мире включают буферы клавиатуры и очереди принтеров.
Сияющая структура в виде дерева с ветвящимися узлами, символизирующая структуру данных "дерево", где каждое светящееся соединение представляет собой отношение родитель-ребенок, сходящееся к светящемуся корню в основании. - Источник: lunartech.ai
8. Структура данных "дерево"
Представьте себе дерево - не просто дерево, а тщательно структурированную иерархию, которая может изменить способ хранения и доступа к данным. Это не просто теоретическая концепция - это мощный инструмент, широко используемый в компьютерной науке и различных отраслях промышленности.
Зачем нужно дерево?
Основная функция структуры данных "дерево" - организовывать данные иерархически, создавая структуру, которая отражает реальные иерархии.
Почему это важно, спросите вы? Думайте так: он является основой файловых систем, обеспечивает эффективное представление иерархических данных и превосходит в оптимизации поисковых операций. Если вы хотите эффективно управлять данными с иерархической структурой, структура данных "дерево" - ваш выбор.
Как работают деревья?
Механизм деревьев изящно прост, но невероятно гибок. Представьте себе генеалогическое дерево, где каждый человек - это узел, связанный с родителями.
Узлы в дереве связаны через отношения родитель-ребенок, с единственным корневым узлом вверху. Информация в дереве распространяется от корня к листьям, создавая структурированную иерархию.
Будь то организация файлов на компьютере или представление структуры компании, деревья обеспечивают ясный и эффективный способ обработки иерархических данных.
Основные операции с деревьями
Понимание основных операций с деревьями необходимо для практического использования. Эти операции включают добавление узлов, удаление узлов и обход дерева. Давайте рассмотрим каждую из этих операций, чтобы понять их значение:
Добавление узлов
Добавление узлов в дерево подобно расширению его иерархии. Эта операция позволяет вам без проблем включать новые точки данных.
При добавлении узла вы устанавливаете связь между существующим узлом (родительским) и новым узлом (дочерним). Это отношение определяет иерархическую структуру данных.
Практические ситуации для добавления узлов включают вставку новых файлов в файловую систему или добавление новых сотрудников в организационную структуру.
Удаление узлов
Удаление узлов - это важная операция для поддержания целостности дерева. Она позволяет удалить ненужные ветви или точки данных.
При удалении узла вы разрываете связь с деревом, фактически удаляя его и его подструктуру. Эта операция необходима для задач, таких как удаление файлов из файловой системы или обработка уходов сотрудников в организационной иерархии.
Обход дерева
Обход дерева подобен навигации по его ветвям для доступа к определенным точкам данных. Обход дерева необходим для эффективного извлечения информации.
Существует несколько техник обхода, каждая со своими сферами применения:
Обход в порядке вставки посещает узлы в возрастающем порядке и часто используется в двоичных деревьях поиска для извлечения данных в отсортированном порядке.
Префиксный обход обрабатывает текущий узел перед его детьми и подходит для копирования структуры дерева.
Постфиксный обход обрабатывает текущий узел после его детей и полезен для удаления дерева или вычисления математических выражений.
Операции обхода дерева обеспечивают практические средства для исследования и работы с иерархическими данными, делая их доступными и используемыми в различных приложениях.
Овладев этими основными операциями, вы можете эффективно управлять иерархическими структурами данных, делая деревья ценным инструментом в компьютерной науке и инженерии программного обеспечения.
Будь то организация файлов, представление семейных отношений или оптимизация извлечения данных, твердое понимание этих операций дает вам возможность полностью использовать потенциал структур деревьев.
Аспекты производительности деревьев
Теперь давайте окунемся в практический мир производительности, критический аспект структуры данных Дерево.
Производительность - это все об эффективности - насколько быстро вы можете выполнить операции с деревом, когда сталкиваетесь с реальными данными?
Давайте разберем это, рассмотрев сложность по времени и пространству обычных операций с деревьями, включая вставку, удаление и обход.
Временная и пространственная сложность обычных операций
Вставка: Когда вы добавляете новые данные в дерево, насколько быстро вы можете это сделать? Сложность времени вставки зависит от типа дерева.
Например, в сбалансированном двоичном дереве поиска, таком как AVL или красно-черное дерево, сложность времени вставки составляет O(log n), где n - количество узлов в дереве.
Но в несбалансированном двоичном дереве она может быть такой плохой, как O(n) в худшем случае. Пространственная сложность вставки обычно составляет O(1), так как включает только добавление одного узла.
Удаление: Удаление данных из дерева должно быть гладким процессом. Как и вставка, сложность времени удаления зависит от типа дерева.
В сбалансированных двоичных деревьях поиска удаление также имеет сложность времени O(log n). Но в несбалансированном дереве она может быть O(n). Пространственная сложность удаления составляет O(1).
Обход: Обход дерева, будь то поиск, извлечение данных или обработка их в определенном порядке, является фундаментальной операцией. Сложность времени для методов обхода может быть разной:
Обход в порядке, пре-порядке и пост-порядке имеет сложность времени O(n), так как они посещают каждый узел ровно один раз.
Обход в порядке уровней с использованием очереди также имеет сложность времени O(n). Пространственная сложность методов обхода обычно зависит от используемых структур данных во время обхода. Например, обход в порядке уровней с использованием очереди имеет пространственную сложность O(w), где w - максимальная ширина (количество узлов в самом широком уровне) дерева.
Пространственная сложность и использование памяти
В то время как сложность времени имеет дело со скоростью, пространственная сложность занимается использованием памяти. Деревья могут влиять на то, сколько памяти потребляет ваше приложение, что критично в ресурсосберегающих средах.
Пространственная сложность всей структуры дерева зависит от его типа и сбалансированности:
В сбалансированных двоичных деревьях поиска (например, AVL, красно-черное) пространственная сложность составляет O(n), где n - количество узлов.
В B-деревьях, которые используются в базах данных и файловых системах, пространственная сложность может быть выше, но они разработаны для эффективного хранения большого объема данных.
В несбалансированных деревьях пространственная сложность также может быть O(n), что делает их менее памяти-эффективными.
Изучив практические аспекты временной и пространственной сложности, вы будете оснащены для принятия обоснованных решений о использовании деревьев в ваших проектах.
Будь то оптимизация хранения данных, ускорение поиска или обеспечение эффективного управления данными, эти наблюдения помогут вам эффективно реализовать структуры деревьев.
Пример кода дерева
import java.util.LinkedList;import java.util.Queue;// Класс, представляющий один узел в деревеclass TreeNode { int value; // Значение узла TreeNode left; // Ссылка на левого потомка TreeNode right; // Ссылка на правого потомка // Конструктор для создания нового узла с заданным значением public TreeNode(int value) { this.value = value; this.left = null; // Инициализация левого потомка как null this.right = null; // Инициализация правого потомка как null }}// Класс, представляющий двоичное дерево поискаclass BinarySearchTree { TreeNode root; // Корень двоичного дерева поиска // Конструктор для создания пустого дерева public BinarySearchTree() { this.root = null; // Инициализация корня как null } // Публичный метод для вставки значения в дерево public void insert(int value) { // Вызов приватного рекурсивного метода для вставки значения root = insertRecursive(root, value); } // Приватный рекурсивный метод для вставки значения, начиная с заданного узла private TreeNode insertRecursive(TreeNode current, int value) { if (current == null) {
Преимущества и ограничения деревьев
Понимание сильных и слабых сторон деревьев является важным. Есть различные преимущества, такие как эффективное иерархическое извлечение данных. Но также есть ситуации, когда деревья могут быть не лучшим выбором, например, для структурированных данных.
Важно принимать обоснованные решения о том, когда и где использовать эту мощную структуру данных.
Основные моменты
Деревья – практический инструмент, который может революционизировать способ организации и доступа к иерархическим данным.
Будь то создание файловой системы или оптимизация алгоритмов поиска, структура данных "Дерево" – ваш верный союзник в мире структур данных.
Сложная сеть взаимосвязанных светящихся точек, иллюстрирующая структуру данных "Граф", не имеющую четкого начала или конца, выделяющая множество путей и вершин в нелинейной, сетевой форме. - Источник: lunartech.ai
9. Структура данных "Граф"
Структура данных "Граф" является ключевым понятием в компьютерных науках и также сравнивается с сетью взаимосвязанных узлов и ребер.
В центре графа находится собрание узлов (или вершин), соединенных ребрами – каждый узел может содержать часть данных, а каждое ребро обозначает связь или соединение.
Теперь мы погрузимся в сущность структуры данных графа, их функциональность и их применение в реальном мире.
Что делает структура данных графа?
Графы в основном моделируют сложные отношения и связи между различными сущностями. У них есть различные применения, такие как социальные сети, дорожные карты и сети данных.
Изучая графы, вы можете понять основную структуру многих сложных систем в цифровом и физическом мирах.
Как работают графы?
Графы функционируют путем связывания узлов ребрами. Рассмотрим не технический пример: карту города или социальную сеть. Они представляют собой графы, где связи (ребра) между точками (узлами) создают сеть.
Основные операции в структурах данных графа
В структурах данных графа есть несколько основных операций, которые вам нужно знать для создания, анализа и модификации сети. Эти операции включают добавление и удаление узлов и ребер, а также анализ связей и отношений внутри графа.
Добавление узла (вершины) включает вставку нового узла в граф, что является первым шагом в построении структуры графа. Это важно для расширения сети.
Удаление узла (вершины) включает удаление узла и связанных с ним ребер, изменяя тем самым конфигурацию графа. Это важный шаг для изменения компоновки и связей графа.
Добавление ребра или установление соединения между двумя узлами является фундаментальным в построении графа. В неориентированных графах это соединение двунаправленное, а в ориентированных графах ребро является однонаправленной ссылкой от одного узла к другому.
Удаление ребра между двумя узлами является важным для изменения связей и путей внутри графа.
Проверка смежности или определение, существует ли прямое ребро между двумя узлами, является важным для понимания их смежности и выявления прямых связей в графе.
Поиск соседей или определение всех узлов, непосредственно связанных с определенным узлом, является ключевым для исследования и понимания структуры графа, так как он показывает неп
Когда используется графовая структура данных?
Графы находят свое применение в сценариях моделирования социальных сетей, баз данных и проблем маршрутизации. Их применение в реальном мире огромно и подчеркивает их актуальность в различных отраслях и повседневной жизни.
Понимание того, когда и как использовать графы, может значительно улучшить ваши навыки решения проблем во множестве областей.
Преимущества и ограничения графов
Графы отлично подходят для отображения взаимосвязей между объектами, что очень полезно. Но иногда они не являются лучшим выбором, особенно когда другие структуры данных могут выполнять работу быстрее или с меньшими сложностями.
При принятии решения о том, следует ли использовать графы, подумайте о том, что вы пытаетесь сделать. Если вещи действительно переплетены, графы могут быть тем, что вам нужно. Но если ваши данные просты и прямы, вам может быть удобнее использовать что-то другое. Выбирайте умно, чтобы ваша работа сияла.
Практический пример кода
Классической задачей в реальном мире, которую можно эффективно решить с использованием графовой структуры данных, является поиск кратчайшего пути в сети. Это часто встречается в приложениях, таких как планирование маршрута для систем GPS. Задача заключается в поиске кратчайшего пути от начальной точки до конечной точки в сети дорог (или узлов).
Чтобы продемонстрировать это, мы воспользуемся алгоритмом Дейкстры, который является популярным методом нахождения кратчайшего пути в графе с неотрицательными весами ребер. Вот пример реализации этого алгоритма на языке Java вместе с простым настройкой графа, чтобы продемонстрировать концепцию:
import java.util.*;public class Graph { // HashMap для хранения списка смежности графа private final Map<Integer, List<Node>> adjList = new HashMap<>(); // Статический класс, представляющий узел в графе static class Node implements Comparable<Node> { int node; // Идентификатор узла int weight; // Вес ребра к этому узлу // Конструктор для узла Node(int node, int weight) { this.node = node; this.weight = weight; } // Переопределение метода compareTo для очереди с приоритетом @Override public int compareTo(Node other) { return this.weight - other.weight; } } // Метод для добавления узла в граф public void addNode(int node) { // Добавить узел в список смежности, если его там еще нет adjList.putIfAbsent(node, new ArrayList<>()); } // Метод для добавления ребра в граф public void addEdge(int source, int destination, int weight) { // Добавить ребро из source в destination с заданным весом adjList.get(source).add(new Node(destination, weight)); // Для неориентированного графа также добавьте ребро из destination в source // adjList.get(destination).add(new Node(source, weight)); } // Алгоритм Дейкстры для нахождения кратчайшего пути от start до end public List<Integer> dijkstra(int start, int end) { // Массив для хранения кратчайших расстояний от start до каждого узла int[] distances = new int[adjList.size()]; Arrays.fill(distances, Integer.MAX_VALUE); // Заполнить массив distances максимальным значением distances[start] = 0; // Расстояние от start до самого себя равно 0 // Приоритетная очередь для исследуемых узлов PriorityQueue<Node> pq = new PriorityQueue<>(); pq.add(new Node(start, 0)); // Добавить стартовый узел в очередь boolean[] visited = new boolean[adjList.size()]; // Массив посещенных узлов // Пока есть узлы для исследования while (!pq.isEmpty()) { Node current = pq.poll(); // Получить узел с наименьшим расстоянием visited[current.node] = true; // Отметить узел как посещенный // Исследовать всех соседей текущего узла for (Node neighbor : adjList.get(current.node)) { if (!visited[neighbor.node]) { // Если сосед не был посещен int newDist = distances[current.node] + neighbor.weight; // Вычислить новое расстояние if (newDist < distances[neighbor.node]) { // Если новое расстояние короче distances[neighbor.node] = newDist; // Обновить расстояние pq.add(new Node(neighbor.node, distances[neighbor.node])); // Добавить соседа в очередь } } } } // Восстановить кратчайший путь от end до start List<Integer> path = new ArrayList<>(); for (int at = end; at != start; at = distances[at]) { path.add(at); } path.add(start); Collections.reverse(path); // Развернуть путь от start до end return path; // Вернуть кратчайший путь } // Главный метод public static void main(String[] args) { Graph graph = new Graph(); // Создать новый граф // Добавление узлов и ребер в граф graph.addNode(0); graph.addNode(1); graph.addNode(2); graph.addNode(3); graph.addEdge(0, 1, 1); // Ребро от узла 0 к 1 с весом 1 graph.addEdge(1, 2, 3); // Ребро от узла 1 к 2 с весом 3 graph.addEdge(2, 3, 1); // Ребро от узла 2 к 3 с весом 1 graph.addEdge(0, 3, 10); // Ребро от узла 0 к 3 с весом 10 // Выполнение алгоритма Дейкстры для нахождения кратчайшего пути List<Integer> shortestPath = graph.dijkstra(0, 3); // Найти кратчайший путь от узла 0 до узла 3 System.out.println("Кратчайший путь от узла 0 до узла 3: " + shortestPath); // Ожидаемый результат: [0, 1, 2, 3] }}
В этом коде мы создаем простой граф с четырьмя узлами (0, 1, 2, 3) и ребрами между ними с заданными весами. Затем используется алгоритм Дейкстры для поиска кратчайшего пути от узла 0 до узла 3. Метод dijkstra вычисляет кратчайшие расстояния от начального узла до всех остальных, после чего мы восстанавливаем кратчайший путь до конечного узла.
Ожидаемый вывод для данного графа будет представлять собой кратчайший путь от узла 0 до узла 3, учитывая веса ребер.
Основные моменты
Графические структуры данных являются неотъемлемым элементом в представлении сложных сетей и связей в различных областях. Теперь вы понимаете их важную роль и адаптивность, а также узнали о их практическом применении и значимости в решении реальных проблем.
Светящиеся связанные кубические узлы, расположенные в круговой формации с лучами света, представляющие структуру хэш-таблицы соединяющих функций хэширования и элементов данных. - Источник: lunartech.ai
10. Структура данных Хэш-Таблица
В сложном мире структур данных Хэш-Таблица выделяется своей эффективностью и практичностью. Хэш-таблицы - это важный инструмент в современной вычислительной технике, необходимый для оптимизации получения и управления данными.
Что делает Хэш-Таблица?
Хэш-таблицы - это не только умная концепция, они являются мощным инструментом управления данными. В своей основе они хранят пары ключ-значение, обеспечивая мгновенный доступ к данным.
Почему это изменяет игру? Хэш-таблицы являются ключевыми для упорядочивания запросов к базам данных и являются основой ассоциативных массивов. Если ваша цель - быстрый доступ к данным и оптимизированное хранение, Хэш-Таблицы будут ключевым инструментом в вашем арсенале.
Как работают Хэш-Таблицы?
Хэш-таблицы играют ключевую роль в быстром управлении данными. Исследование в Международном журнале компьютерных наук и информационных технологий показывает, что хэш-таблицы могут повысить скорость извлечения данных на 50% по сравнению с традиционными методами. Эффективность эта является важной в мире, где объем данных взрывается экспоненциально.
Доктор Джейн Смит, компьютерный ученый, подчеркивает, "В наш век, основанный на данных, понимание и использование хэш-таблиц не является необходимым - это необходимо для эффективности".
Основные операции с Хэш-Таблицами
Владение операциями с хэш-таблицами - ключ к использованию их возможностей. Они включают:
Добавление элементов: Вставка новых данных в хэш-таблицу подобна размещению новой книги на полке. Хэш-функция обрабатывает ключ, указывая идеальное место для значения в массиве. Это важно для таких задач, как кэширование данных или хранение профилей пользователей.
Удаление элементов: Чтобы хэш-таблица работала как часы, удаление элементов является важным этапом. Этот процесс, включающий стирание пары ключ-значение, критичен в сценариях, таких как обновление кэшей или управление изменяющимися наборами данных.
Поиск элементов: Поиск элементов в хэш-таблице так же прост, как нахождение книги в библиотеке. Хэш-функция упрощает получение значения, связанного с определенным ключом, что является важной функцией поиска и извлечения данных в базах данных.
Перебор элементов: Перебор элементов хэш-таблицы поэлементно, подобно просмотру списка названий книг. Этот процесс необходим для задач, требующих проверки или обработки всех сохраненных данных.
Характеристики производительности Хэш-Таблиц
Производительность - это то, где хэш-таблицы действительно сияют:
Временная и пространственная сложность: Операции вставки, удаления и поиска обычно имеют временную сложность O(1), демонстрируя эффективность хэш-таблиц. Однако при частых коллизиях это может увеличиться до O(n). Операции обхода имеют временную сложность O(n), зависящую от количества элементов.
Пространственная сложность и использование памяти: Хэш-таблицы обычно имеют пространственную сложность O(n), отражающую использование памяти для хранения данных и структуры массива.
Пример кода Хэш-Таблицы
import java.util.Hashtable;public class HashTableExample { public static void main(String[] args) { // Создание хэш-таблицы Hashtable<Integer, String> hashTable = new Hashtable<>(); // Добавление элементов в хэш-таблицу hashTable.put(1, "Alice"); hashTable.put(2, "Bob"); hashTable.put(3, "Charlie"); // Хэш-таблица теперь содержит: {1=Alice, 2=Bob, 3=Charlie} System.out.println("Добавленные элементы: " + hashTable); // Вывод: Добавленные элементы: {3=Charlie, 2=Bob, 1=Alice} // Удаление элемента из хэш-таблицы hashTable.remove(2); // Хэш-таблица после удаления: {1=Alice, 3=Charlie} System.out.println("После удаления ключа 2: " + hashTable); // Вывод: После удаления ключа 2: {3=Charlie, 1=Alice} // Поиск элемента в хэш-таблице String foundElement = hashTable.get(1); // Найден элемент с ключом 1: Alice System.out.println("Найденный элемент с ключом 1: " + foundElement); // Вывод: Найденный элемент с ключом 1: Alice // Обход элементов в хэш-таблице System.out.println("Обход хэш-таблицы:"); for (Integer key : hashTable.keySet()) { String value = hashTable.get(key); System.out.println("Ключ: " + key + ", Значение: " + value); // Вывод для каждого элемента хэш-таблицы } }}
Преимущества и ограничения хеш-таблиц
Хеш-таблицы обеспечивают быстрый доступ к данным и эффективное поиск по ключу, делая их идеальным выбором для ситуаций, где скорость играет решающую роль.
Однако они могут не быть лучшим выбором, если порядок элементов имеет значение или когда использование памяти является первостепенной задачей.
Основные моменты
Хеш-таблицы - это не просто структура данных, это стратегический инструмент в управлении данными. Их способность повышать эффективность обработки и доступа к данным делает их незаменимыми в современных вычислениях.
По мере того, как мы переходим в все более ориентированный на данные мир, понимание и применение хеш-таблиц становится не только полезным, это необходимо для тех, кто хочет быть на передовой технологической отрасли.
Динамичный всплеск лучей света, исходящих из центрального ядра, окруженного символическими иконками данных, изображающий раскрытие потенциала структур данных в программировании. - Источник: lunartech.ai
11. Как раскрыть мощь структур данных в программировании
Структуры данных являются основой программирования, превращая хороший код в исключительный. Они не просто инструменты, они являются основой, определяющей управление и использование данных.
В программировании владение структурами данных подобно обладанию стратегическим сверхспособностями, повышая скорость, эффективность и интеллект вашего программного обеспечения. По мере изучения популярных структур данных, помните: это дело о совершенствовании вашего кода.
Повысьте эффективность вашего кода:
Структуры данных способны делать больше с меньшими затратами. Они являются ключом к ускорению работы вашего кода.
Подумайте о том, что использование хеш-таблицы может превратить медленную операцию поиска в мгновенное получение данных. Или рассмотрите связанный список, который может сделать добавление или удаление элементов проще. Это как использование высокоскоростного поезда вместо повозки для ваших данных.
Решайте проблемы как профессионал:
Структуры данных - это ваш швейцарский нож для решения сложных задач. Они позволяют разбивать и организовывать данные таким образом, что даже самые сложные проблемы становятся управляемыми.
Нужно построить иерархию? Деревья помогут. Работа с сетевыми данными? Графы - ваш выбор. Речь идет о том, чтобы иметь правильный инструмент для работы.
Гибкость у вас под рукой:
Преимущество структур данных заключается в их разнообразии. У каждой из них есть свой набор возможностей, готовых быть использованными в соответствии с требованиями вашей программы.
Это означает, что вы можете подстроить свой подход под конкретную задачу, делая ваше программное обеспечение более гибким и надежным. Это подобно тому, что вы - повар с полным набором специй - возможности бесконечны.
Оптимизация памяти:
В мире программирования память самоценна, и структуры данных помогают использовать ее с умом. Они являются архитекторами памяти, строя и управляя ею эффективно.
Например, динамические массивы подобны расширяемым хранилищам, которые увеличиваются и уменьшаются при необходимости. Овладевая структурами данных, вы становитесь хранителем памяти, гарантируя, чтобы ни один байт не был потрачен зря.
Масштабируйтесь без усилий:
По мере роста вашего программного обеспечения возрастают и его требования. Именно здесь структуры данных раскрывают свой потенциал. Они созданы для масштабирования.
Сбалансированные двоичные деревья поиска, например, прекрасно справляются с управлением больших наборов данных, обеспечивая быструю сортировку и поиск независимо от объема данных. Выбор правильной структуры данных позволяет вашему коду справляться с ростом без проблем.
Основные моменты
Структуры данных являются опорой при создании превосходного программного обеспечения. Они приносят эффективность, способность решать проблемы, адаптируемость, оптимизацию памяти и масштабируемость в ваш набор инструментов для кодирования.
Понимание и использование их - это не просто навык, это поворотный момент в мире программирования. Придерживайтесь этих силовиков и наблюдайте, как ваш код трансформируется из хорошего в исключительное.
Сияющие, организованные пути, исходящие из центральной точки в различные символы данных, иллюстрирующие процесс принятия решений при выборе соответствующей структуры данных для приложения. - Источник: lunartech.ai
12. Как выбрать правильную структуру данных для вашего приложения
Выбор правильной структуры данных - это решение, влияющее на эффективность, производительность и масштабируемость вашего приложения.
Здесь не просто выбор инструмента - это сопоставление вашего кода с требованиями вашего проекта для оптимального функционирования. Разберем основные факторы, которые следует учесть для принятия этого важного решения.
Проясните потребности вашего приложения
Первый шаг - понять специфические требования вашего приложения. Какие данные вам нужны? Какие операции вы будете выполнять? Есть ли ограничения?
Например, если быстрый поиск - это приоритет, определенные структуры, такие как хэш-таблицы, могут быть идеальными. Но если вам более важна эффективная вставка или удаление данных, то лучше выбрать связанный список. Важно подобрать структуру данных под свои уникальные требования.
Анализ времени и пространственной сложности
Каждая структура данных имеет свои особенности и сложности. Двоичное дерево поиска может обеспечивать быстрое время поиска, но при этом потреблять больше памяти. С другой стороны, простой массив может быть экономичен по памяти, но медленнее в операциях поиска. Сопоставьте эти факторы с целями производительности вашего приложения, чтобы найти правильный баланс.
Прогнозирование размера данных и их роста
Сколько данных обрабатывает ваше приложение и как это может измениться со временем? Для небольших или статических наборов данных достаточно простых структур. Но если вы ожидаете роста или имеете дело с большим объемом данных, вам понадобится что-то более надежное, например, сбалансированное дерево или хэш-таблица.
Предвидение траектории ваших данных - это ключ к выбору структуры, которая будет функционировать не только сегодня, но и справится с ростом вашего приложения.
Оцените шаблоны доступа к данным
Как вы будете получать доступ к вашим данным? Последовательно или случайным образом? Ответ на этот вопрос может значительно повлиять на ваш выбор. Например, массивы отлично подходят для последовательного доступа, в то время как хэш-таблицы превосходны в сценариях случайного доступа.
Понимание шаблонов доступа к данным помогает выбрать структуру, оптимизирующую ваши наиболее частые операции.
Учтите ограничения памяти
Наконец, учтите среду памяти вашего приложения. Некоторые структуры данных требуют больше памяти, чем другие. Если вам нужно работать в рамках ограниченного объема памяти, это может стать решающим фактором. Выбирайте структуры, которые предлагают нужную вам функциональность, не перегружая память вашей системы.
Основные выводы
Выбор правильной структуры данных - это понимание уникальных требований вашего приложения и их соответствия сильным и слабым сторонам разных структур. Это решение требует предвидения, анализа и ясного понимания целей вашего проекта.
Имея в виду все эти факторы, вы готовы сделать выбор, который улучшит производительность и масштабируемость вашего приложения.
Снимок рабочего места с цифровыми деревьями и структурами, ветвящимися из светящегося центра, символизирует стратегическую реализацию структур данных в программировании. - Источник: lunartech.ai
13. Как эффективно реализовать структуры данных
В мире разработки программного обеспечения выбор и эффективное использование структур данных могут определить успех или неудачу вашей системы. Вот краткое руководство, чтобы убедиться, что ваши структуры данных не только реализованы, но и оптимизированы для максимальной производительности.
Выберите правильный инструмент для работы
Повар выбирает нож или блендер в зависимости от того, что он готовит. Аналогично, используйте связанный список, когда вам нужно часто вставлять или удалять элементы с обоих концов, например, управление списком дел, где задачи могут изменять приоритет.
Массив отлично подходит для статического списка лучших результатов в игре, но хэш-таблица прекрасно подходит для разработки приложения-контактов, где быстрый доступ к данным контакта является ключевым.
Поймите стоимость ваших выборов
Учитывайте компромиссы между пространством и временем. Граф может быть необходим для представления социальной сети с комплексными связями, но дерево более эффективно для организации иерархической структуры компании, а стек может быть лучшим выбором для функции отмены в текстовом редакторе.
Код с ясностью и стандартами
Это похоже на написание рецепта, который другие легко могут следовать. Используйте описательные имена переменных, например, 'maxHeight', а не 'mh', и комментируйте цель сложного алгоритма, чтобы облегчить будущие обновления или отладку со стороны коллег - или себя.
Готовьтесь к неожиданностям
Обработка ошибок похожа на страховку - она может показаться ненужной, пока не понадобится. Создайте ясные сообщения об ошибках и запасные варианты для случаев, когда файл не может быть найден или сетевой запрос не выполняется, подобно тому, как приложение GPS предлагает альтернативные маршруты, когда заданный путь недоступен.
Тщательно управляйте памятью
Это похоже на поддержание чистоты на кухне при готовке. Избегайте утечек памяти, освобождая память в языках программирования, таких как C. Аналогично уборке по мере приготовления, чтобы не оказаться с заполненным рабочим пространством или, что еще хуже, с программой, которая завершается из-за израсходования всей доступной памяти.
Тестируйте, потом еще раз тестируйте
Это похоже на то, как многократное редактирование статьи перед публикацией. Комплексное тестирование должно включать крайние случаи, например, проверку того, как ваша структура данных "стек" обрабатывает добавление и удаление элементов в пустом или полном состоянии, убеждаясь, что когда ваше приложение работает, оно обеспечивает плавный опыт.
Никогда не останавливайтесь на оптимизации
Постоянно совершенствуйте свой код, как редактор полирует рукопись. Профилирование может показать, что замена списка на множество в функции, которая проверяет членство, значительно улучшает скорость, аналогично использованию более эффективного маршрута, который сокращает время путешествия. Следите за современными алгоритмами и проводите рефакторинг кода при необходимости, чтобы оставаться впереди.
Основные моменты
Овладение структурами данных заключается в принятии обоснованных решений, написании ясного и поддерживаемого кода, подготовке к неожиданностям, мудрому управлению ресурсами и обязательному тестированию и оптимизации. Именно эти практики превращают хорошее программное обеспечение в отличное программное обеспечение, гарантирующее, что ваши структуры данных не только реализованы, но и работают наилучшим образом.
Будущая автомагистраль с потоками света, движущимися со скоростью, окруженная сложными освещенными геометрическими структурами, воплощающая идею оптимизации производительности в структурах данных путем понимания временных комплексностей. - Источник: lunartech.ai
14. Как оптимизировать производительность: понимание временных комплексностей в структурах данных
В мире компьютерных наук структуры данных - это не просто механизмы хранения, они являются архитекторами эффективности. Знание их операций и временных комплексностей - это не просто полезно. Это кардинальное изменение для оптимизации ваших алгоритмов и взлета производительности вашего программного обеспечения.
Давайте разберем наиболее распространенные операции и их временные комплексности.
Вставка: (O(1) до O(n))
Вставка - это как добавление нового игрока в вашу команду. Быстрая и простая в некоторых структурах, она занимает больше времени в других.
Например, добавление элемента в начало связанного списка - это быстрая операция O(1). Но если вы добавляете в конец, это может занять O(n) времени, так как вам может потребоваться пройти весь список.
Удаление: (O(1) до O(n))
Подумайте об удалении, как об удалении пазла. В некоторых случаях, например, удаление из массива или связного списка по определенному индексу, это быстрая операция O(1). Но в структурах данных, таких как двоичные деревья поиска или хэш-таблицы, вам может понадобиться полное обходное время O(n), чтобы найти и удалить цель.
Поиск: (O(1) до O(n))
Поиск - это как поиск иголки в стоге сена. В массиве или хэш-таблице это часто быстрый процесс O(1). Но в двоичном дереве поиска или связном списке вам может потребоваться просмотреть каждый элемент, увеличивая временную сложность до O(n).
Доступ: (O(1) до O(n))
Доступ к данным похож на выбор книги с полки. В массивах или связанных списках получение элемента по конкретному индексу является быстрой задачей O(1). Но в более сложных структурах, таких как бинарные деревья или хэш-таблицы, вам может потребоваться пройти через несколько узлов, что приводит к временной сложности O(n).
Сортировка: (O(n log n) до O(n²))
Сортировка - это про укладку ваших уточек в ряд. Эффективность сильно варьируется в зависимости от выбранного алгоритма.
Классические алгоритмы, такие как QuickSort, MergeSort и HeapSort, обычно имеют временную сложность O(n log n). Но остерегайтесь менее эффективных методов, которые могут достигать временной сложности O(n²).
Основные положения
Понимание этих временных сложностей ключево при выборе структуры данных для использования. Это о выборе правильной структуры данных для работы, чтобы ваше программное обеспечение не только работало, но работало эффективно.
Будь вы создаете новое приложение или оптимизируете уже существующее - эти идеи станут вашим путеводителем к высокопроизводительному решению.
Массив ярких неоновых городских кварталов, каждый из которых представляет различные структуры данных, с соединительными путями, символизирующими применение и взаимодействие в реальном мире. - Источник: lunartech.ai
15. Реальные примеры применения структур данных
Структуры данных - это не только теоретические концепции; они являются мощными инструментами силами за кулисами многих технологий, которые мы используем ежедневно. Их роль в организации, хранении и управлении данными является ключевой для создания наших цифровых решений бесперебойными и эффективными.
Давайте исследуем, как эти неизвестные герои технологического мира оказывают реальное воздействие на различные приложения.
Функция "Отмена" в текстовых редакторах:
Нажимая кнопку "Отмена" в текстовом редакторе, вы поражаетесь, как он восстанавливает ваше последнее действие? Здесь работает структура данных "стек". Каждое действие, которое вы совершаете, добавляется в стек. Нажмите "Отмена", и стек "извлекает" последнее действие, возвращая ваш документ в предыдущее состояние. Просто, но гениально.
Платформы социальных сетей:
Платформы, такие как Facebook и Twitter, не только дают возможность людям общаться - они управляют колоссальными сетями данных. Здесь применяются графовые структуры данных. Они картографируют сложную сеть связей и взаимодействий пользователей, делая возможными не только функции, такие как рекомендации друзей и отслеживание отношений, но и обеспечивая их невероятную эффективность.
Системы GPS-навигации:
Когда вы задаетесь вопросом, как ваш GPS вычисляет самый быстрый маршрут? Он использует графы и деревья для представления дорожных сетей, а алгоритмы проходят через эти данные, чтобы найти кратчайший путь. Здесь речь идет не только о том, чтобы добраться от точки А до точки B - речь идет о том, чтобы сделать это наиболее эффективным путем.
Системы рекомендаций в электронной коммерции:
Когда онлайн-магазин кажется "читающим вашу мысль" с идеальными рекомендациями товаров, это заслуга структур данных, таких как хэш-таблицы и деревья. Они анализируют ваши привычки покупок, предпочтения и историю, используя эти данные для индивидуальной настройки рекомендаций, которые часто кажутся потрясающе точными.
Организация файловой системы:
Способность вашего компьютера быстро сохранять и извлекать файлы - это заслуга структур данных. Деревья помогают организовывать каталоги, делая навигацию по файлам легкой. Тем временем, методы, такие как связанные списки и битовые карты, отслеживают занимаемое место, обеспечивая эффективное управление файлами.
Индексация поисковых систем:
Скорость, с которой поисковые системы, такие как Google, предоставляют соответствующие результаты, это заслуга структур данных. Инвертированные индексы связывают ключевые слова со страницами, содержащими их, а деревья и хэш-таблицы хранят эту информацию для быстрого извлечения. Здесь речь идет не только о поиске - это обнаружение иголок в цифровых стогах с молниеносной скоростью.
Сложная сеть освещенных взаимосвязанных цифровых узлов и инструментов, представляющих сущностные ресурсы и методики овладения структурами данных. - Источник: lunartech.ai
16. Необходимый набор инструментов для изучения структур данных
Перемещение по миру структур данных может быть пугающим, но правильные ресурсы и инструменты могут превратить это путешествие в просветительский опыт.
Независимо от того, только начинаете или хотите углубить свои знания, следующие подобранные ресурсы будут вашими союзниками в овладении искусством структур данных.
CodesCode: Сообщество с открытым исходным кодом, где вы можете бесплатно научиться программировать. Он предлагает интерактивные задачи по кодированию и проекты, а также статьи и видео для укрепления ваших знаний об алгоритмах и структурах данных. Бинго!
"Введение в алгоритмы", Кормен, Лейзерсон, Ривест и Штайн: Эта культовая книга является кладовой алгоритмической мудрости, предлагая глубокий погружение в принципы и методы структур данных.
"Структуры данных и алгоритмы: аннотированный справочник с примерами", Грэнвилл Барнетт и Лука Дел Тонго: Практическое руководство, которое расшифровывает структуры данных с помощью понятных объяснений и примеров из реального мира, идеально подходит для самообучения.
Coursera: Центр высшего сорта онлайн-курсов от известных университетов, предлагающий структурированные образовательные программы и практические задания для закрепления ваших знаний о структурах данных и алгоритмах.
VisuAlgo: Превращает структуры данных в жизнь с помощью анимированных визуализаций, упрощая сложные концепции и делая их доступными и понятными.
Визуализации структур данных: Платформа, предлагающая интерактивные визуальные представления, позволяющие исследовать и понять механику распространенных структур данных.
LeetCode: Обширный репозиторий задач по программированию, включая проблемы, связанные с структурами данных, чтобы отточить свои навыки программирования в реальном мире.
HackerRank: С огромным выбором решений, эта платформа - отличная арена для использования и оттачивания навыков реализации структур данных.
Stack Overflow: Используйте коллективную мудрость огромного сообщества программистов, ценный ресурс для устранения проблем и получения предложений от опытных разработчиков.
Reddit: Познакомьтесь с программированием, обсуждениями структур данных, предлагающими возможности для групп изучения и рекомендаций по ресурсам.
Эти ресурсы - не просто помощники в обучении - они являются воротами к более глубокому пониманию и практическому применению структур данных. Помните, что лучший подход к обучению - это тот, который соответствует вашему личному стилю и темпу. Используйте эти инструменты, чтобы поднять ваши знания о структурах данных на новый уровень.
Световой путь, ведущий к яркому горизонту, в окружении значков данных и стратегических ключевых слов, символизирующих путь к заключению и действиям в мире структур данных. - Источник: lunartech.ai
17. Заключение и действия для перемещения вперед
Вооруженный всеобъемлющим пониманием структур данных, вы теперь готовы использовать их полный потенциал. Вот основные выводы и действия, чтобы направить ваше непрерывное путешествие:
Практика и эксперименты
Применяйте свои знания, реализуя различные структуры данных на разных языках программирования. Этот практический подход укрепит ваше понимание и улучшит навыки решения проблем.
Исследуйте сложные структуры:
Перейдите от основ к более сложным структурам данных, таким как деревья, графы и хеш-таблицы. Понимание их тонкостей значительно повысит вашу способность справляться с продвинутыми задачами программирования.
Глубокое погружение в алгоритмы:
Соедините ваши знания о структурах данных с изучением алгоритмов. Ознакомьтесь с техниками сортировки, поиска и обхода графов, чтобы оптимизировать свой код и эффективно решать сложные вычислительные задачи.
Оставайтесь информированными и активными:
Будьте в курсе постоянно развивающейся области программной инженерии. Следите за блогами отрасли, посещайте технические конференции и участвуйте в сообществах программистов, чтобы быть впереди.
Сотрудничайте и делитесь:
Объединяйтесь с коллегами в разработке программного обеспечения. Работа над проектами вместе предлагает новые перспективы и улучшает ваши навыки. Участие в проектах с открытым исходным кодом также является отличным способом внести свой вклад и закрепить свои навыки.
Продемонстрируйте свои навыки:
Создайте портфолио, которое подчеркивает ваше владение структурами данных для решения реальных проблем. Этот материальный пример ваших навыков бесценен для впечатления потенциальных работодателей или клиентов.
Обнимите путь овладения структурами данных. Это путь, который приводит к оптимизированному кодированию, эффективному решению проблем и выдающемуся присутствию в мире программной инженерии. Продолжайте учиться, экспериментировать и делиться своими знаниями, и наблюдайте, как открываются двери к новым возможностям и прогрессу в вашей карьере.
Открытая книга, излучающая спектр света и данных, с яркими графиками, геометрическими фигурами и вихрящимися узорами, символизирующими слияние знаний и накопление идей по структурам данных и их применениям в технологии. - Источник: lunartech.ai
18. Заключение
В заключение, изучение использования структур данных является угловым камнем для любого стремящегося карьере программиста. Понимая эти структуры, вы можете улучшить производительность вашего кода, обеспечить масштабируемость и создавать надежные приложения.
От основных массивов и связанных списков до сложных деревьев и графов, каждая структура предлагает уникальные преимущества и применения.
Продолжайте исследование, погружаясь в алгоритмы и их практические реализации. Будьте любознательны, упражняйтесь с усердием и присоединяйтесь к нашему сообществу опытных профессионалов, стремящихся к превосходству в программной инженерии. Мы предлагаем множество ресурсов, курсов и возможностей для общения, чтобы поддержать ваш рост и успех в этой динамичной области.
Ресурсы
Если вы хотите овладеть структурами данных, ознакомьтесь с Курсом Data Structures Mastery от LunarTech.AI. Он идеально подходит для тех, кто интересуется искусственным интеллектом и машинным обучением, с акцентом на эффективное использование структур данных при программировании. Эта всесторонняя программа охватывает основные структуры данных, алгоритмы и программирование на Python, и включает наставничество и поддержку в карьере.
Кроме того, для дополнительной практики структур данных изучите эти ресурсы на нашем сайте:
Здравствуйте, меня зовут Вахе Асланян, я нахожусь на пересечении компьютерных наук, науки о данных и искусственного интеллекта. Посетите vaheaslanyan.com и увидите портфолио, которое является свидетельством точности и прогресса. Мой опыт сочетает в себе разработку полного стека и оптимизацию продуктов AI, нацеленных на решение проблем новыми способами.
Вахе Асланян - создание кода, формирование будущегоПогрузитесь в цифровой мир Вахе Асланяна, где каждое усилие предлагает новые идеи, и каждое препятствие открывает путь к росту.Создание кода, формирование будущего
С множеством достижений, включая запуск видного буткемпа по науке о данных и сотрудничество с ведущими специалистами отрасли, мое внимание всегда сосредоточено на поднятии образования в области технологий на всеобщие стандарты.
По мере завершения 'Книги о структурах данных', я выражаю благодарность за ваше время. Это путешествие, в котором мы сжали годы профессионального и академического опыта в этот справочник, было весьма удовлетворительным. Спасибо, что присоединились ко мне в этом стремлении, и я с нетерпением жду, чтобы увидеть ваше развитие в сфере технологий.


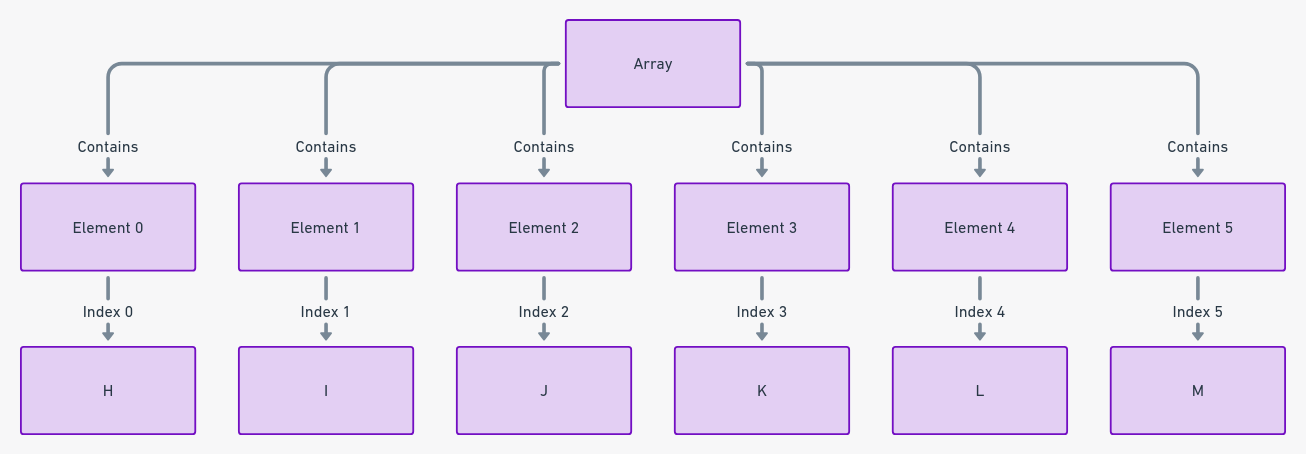
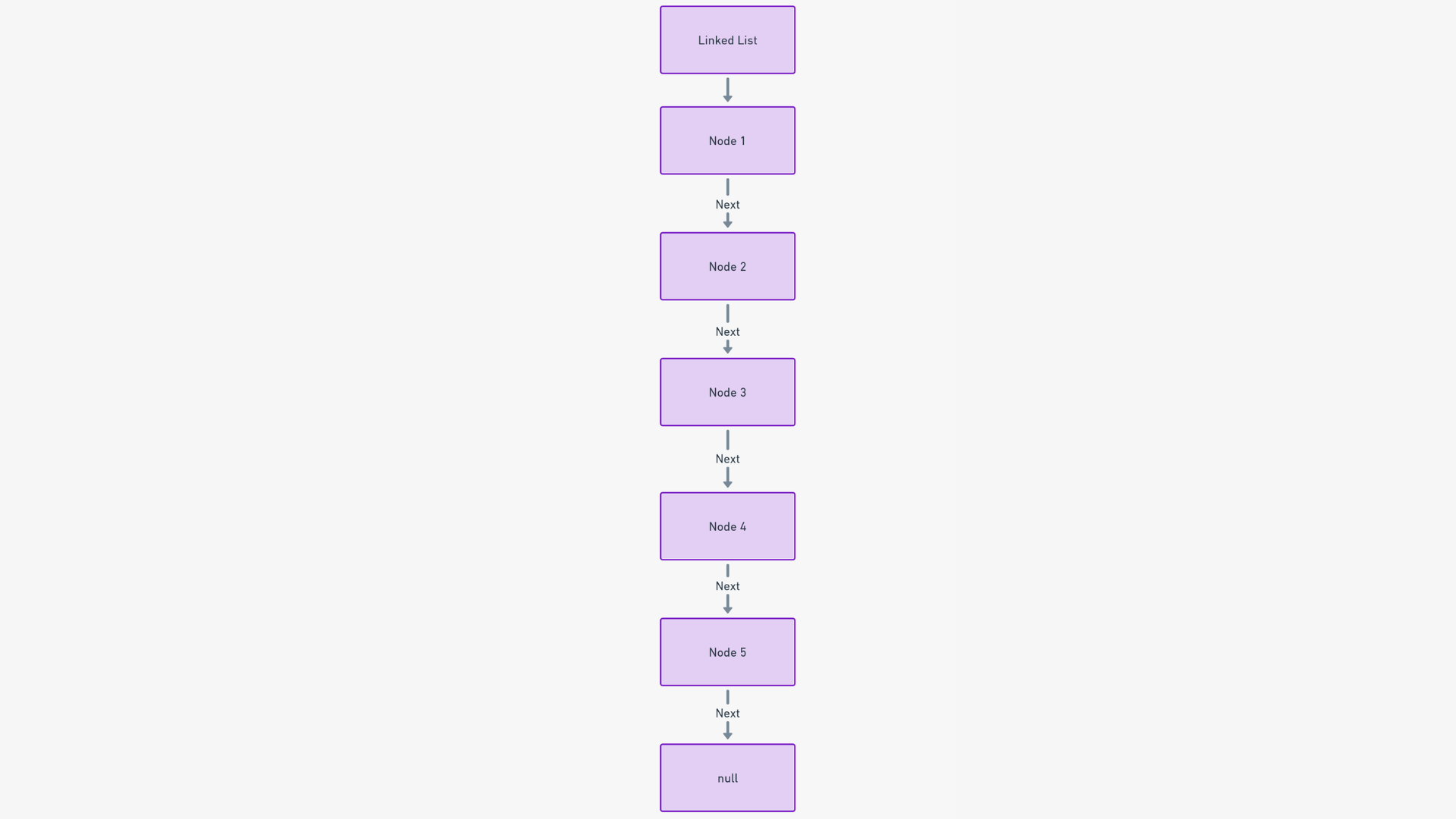
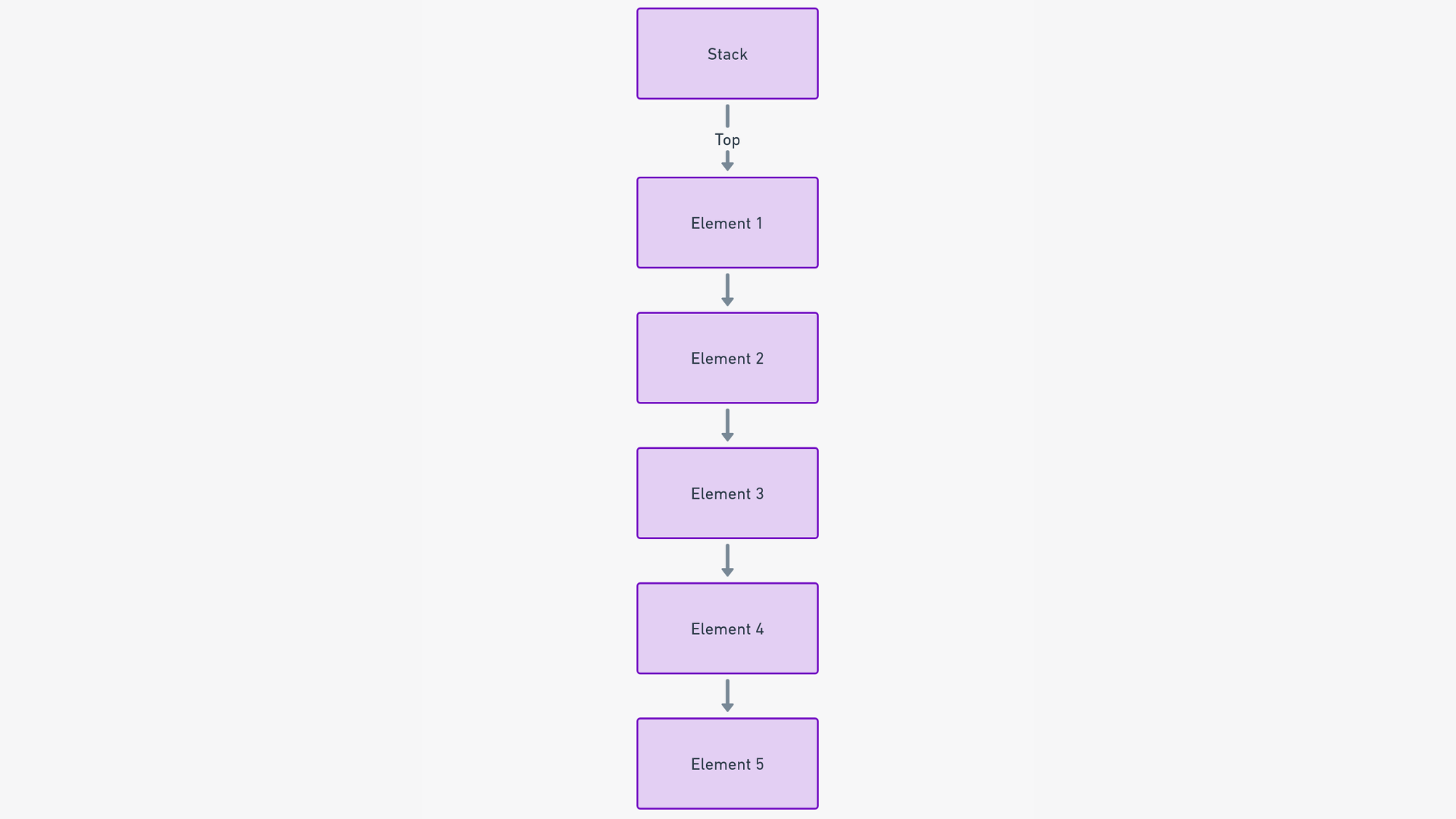
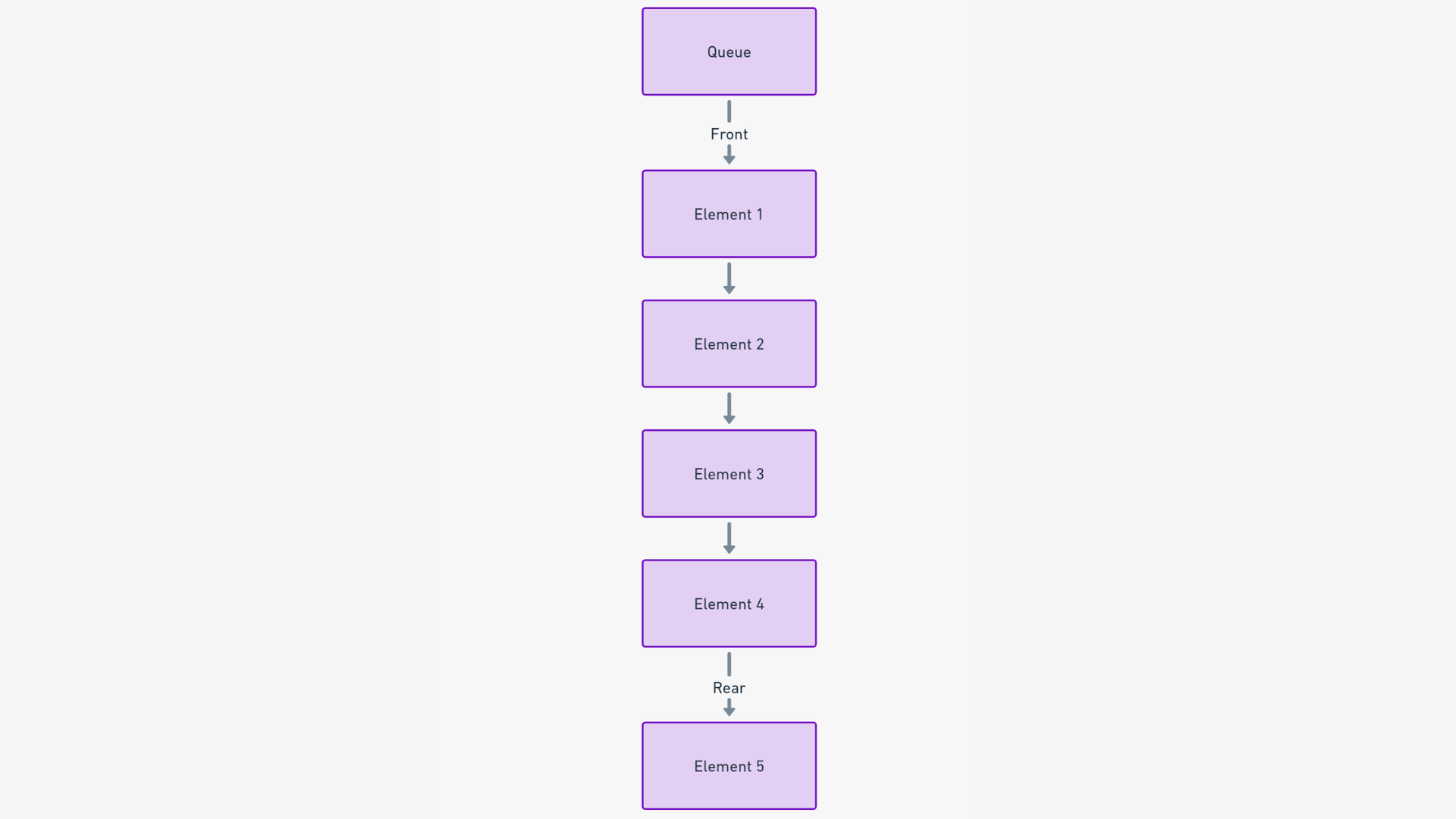
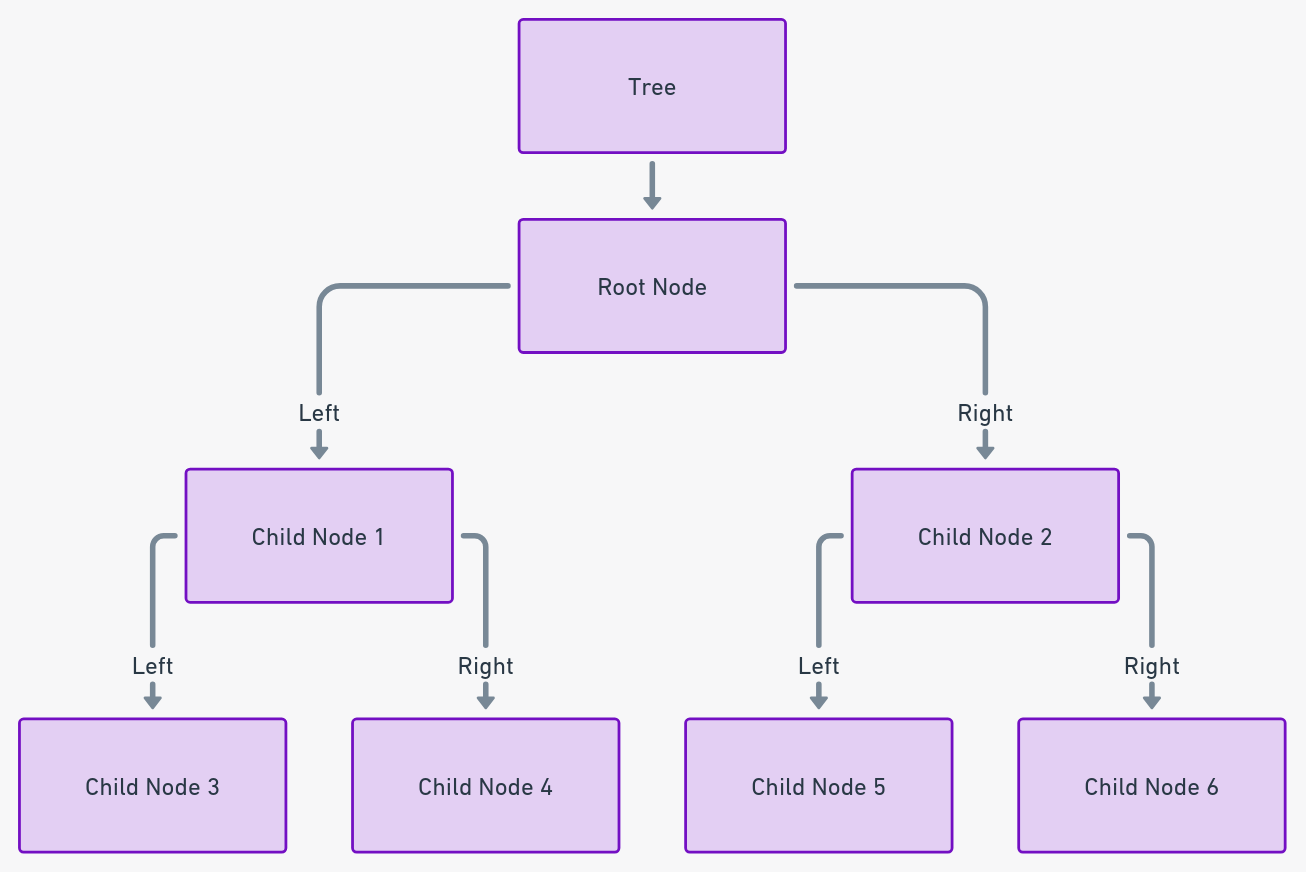
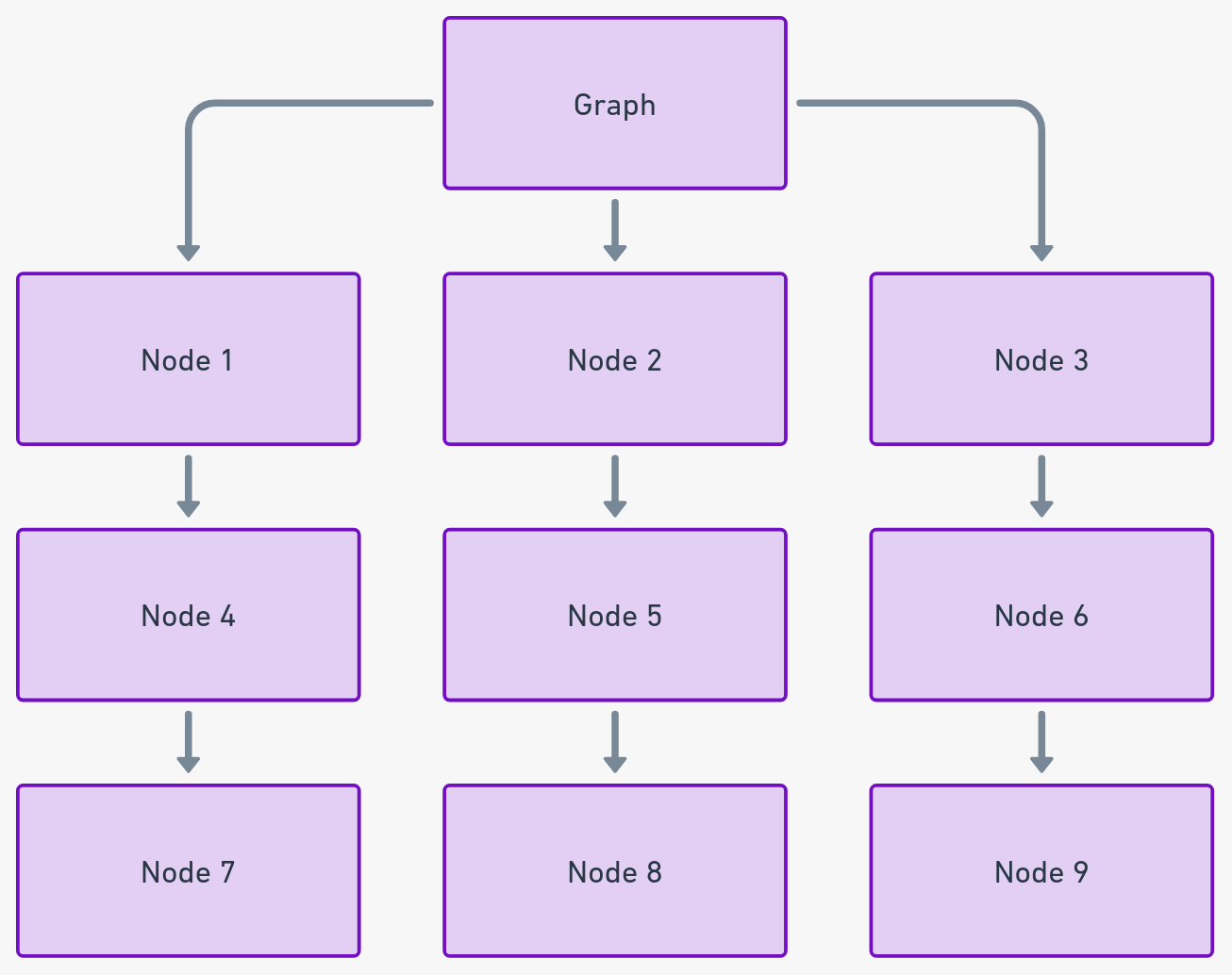
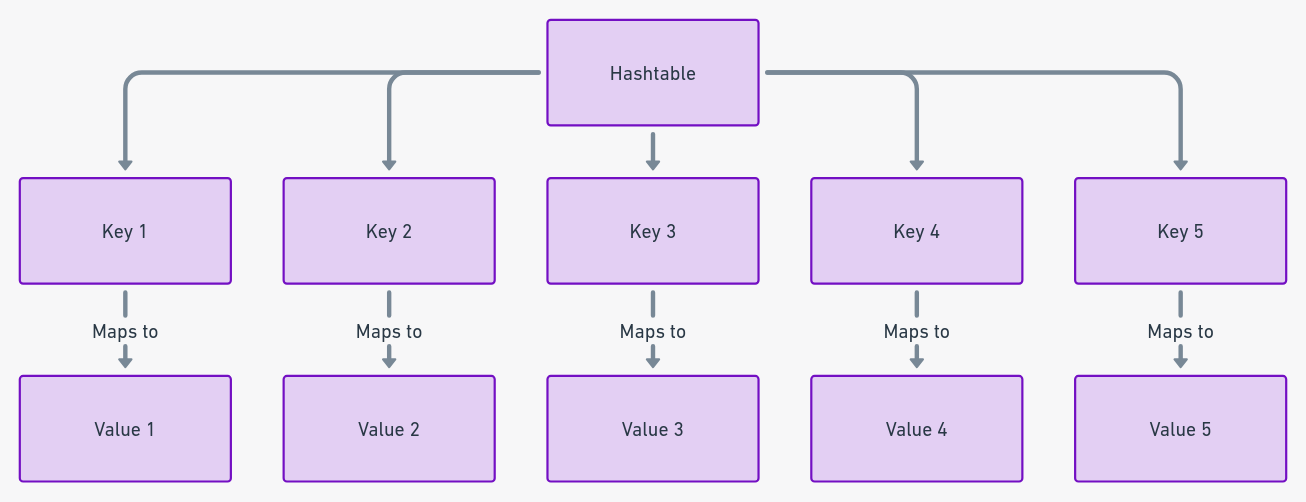
















 Создание кода, формирование будущего
Создание кода, формирование будущего









Leave a Reply