Rolex Генератор лексем с поддержкой Unicode на C#
Cоздание быстрых и удобных сканеров /лексеров в основных языках .NET
Введение
Лексический анализ часто является первым этапом разбора. Прежде чем мы сможем проанализировать структурированный документ, мы должны разбить его на лексические элементы, называемые токенами или лексемами. Большинство анализаторов используют этот подход, беря токены из лексера и используя их в качестве основного ввода. Лексеры также могут использоваться вне анализаторов, они присутствуют в таких инструментах, как минификаторы или даже простые сканеры, которым просто нужно искать шаблоны в документе, поскольку лексеры по своей сути работают как составные сопоставители регулярных выражений.
Rolex генерирует лексеры, чтобы сделать этот процесс незаметным и относительно интуитивным, как при их определении, так и при использовании. Сгенерированный код Rolex использует простой, но надежный и быстрый алгоритм DFA. Все сопоставления выполняются за линейное время. Вы не можете передавать ему потенциально квадратичные выражения, так как он не осуществляет откат. Регулярные выражения просты. Нет захватывающих групп, потому что они не нужны. Нет якорей, потому что они усложняют сопоставление и не очень полезны в токенизаторах. Нет ленивых выражений, но есть возможность определения многобуквенных условий окончания, которые являются 80% от dessrw, для которых обычно используются ленивые выражения.
Главное преимущество использования Rolex – это скорость. Сгенерированные лексеры очень быстрые. Главный недостаток использования Rolex, помимо относительно ограниченного синтаксиса регулярных выражений, заключается во времени, которое может потребоваться для генерации сложных лексеров. В основном вы платите за производительность Rolex заранее, во время сборки.
Обновление: Заменен движок FA на более быструю вариант, чтобы ускорить генерацию кода и исправить некоторые ошибки. Убрана опция “prototype”.
Обновление 2: Дополнительно улучшена производительность движка FA и добавлена функция externaltoken.
Обновление 3: Упрощено представление DFA – сведено к массиву целых чисел. Добавлена возможность отображения графов DFA и NFA лексера с использованием GraphViz.
Обновление 4: Добавлен вывод графа, исправлена ошибка в генерации кода и улучшен результат.
Концептуализация этой путаницы
Интерфейс командной строки Rolex
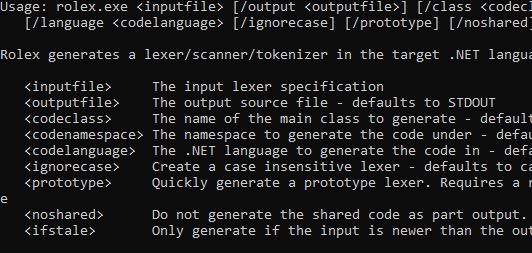
Использование Rolex достаточно просто. Вот экран использования:
Использование: rolex.exe <inputfile> [/output <outputfile>] [/class <codeclass>] [/namespace <codenamespace>] [/language <codelanguage> [/external <externaltoken>] [/ignorecase] [/noshared] [/ifstale] [/nfagraph <dfafile>] [/dfagraph <nfafile>] [/graph <graphfile>] [/dpi <dpi>]Rolex генерирует лексер/сканер/токенизатор на целевом языке .NET <inputfile> Спецификация входного лексера <outputfile> Выходной исходный файл - по умолчанию STDOUT <codeclass> Имя основного класса для генерации - по умолчанию определенное от<outputfile> <codenamespace> Пространство имен для генерации кода - по умолчанию нет <codelanguage> Язык .NET для генерации кода - по умолчанию определенный от<outputfile> <externaltoken> Пространство имен внешнего токена, если он используется - по умолчанию внешний отсутствует <ignorecase> Создать неразличающий регистр лексер - по умолчанию регистрозависимый <noshared> Не генерировать общий код как часть выхода - по умолчанию генерация общего кода <ifstale> Генерировать только если входной файл новее выходного <staticprogress> Не использовать динамические функции консоли для индикаторов прогресса <nfafile> Записать граф NFA лексера в указанный файл изображения.* <dfafile> Записать граф DFA лексера в указанный файл изображения.* <graphfile> Записать все отдельные правила DFA в граф.* <dpi> DPI для выводимых графов - по умолчанию 300.* * Требуется установленный и находящийся в PATH GraphViz
inputfile(обязательный параметр) – указывает файл спецификации лексера, из которого будет сгенерирован код. Далее будет описано, что такое эти файлы.outputfile– указывает файл, в который будет сгенерирован код, или по умолчанию будет использоватьсяstdout.codeclass– указывает имя сгенерированного класса токенизатора. По умолчанию оно получается из значенияoutputfile.codelanguage– указывает язык, для которого будет сгенерирован код. Он определяется по расширению файлаoutputfile, если оно указано, в противном случае по умолчанию используется C#.codenamespace– указывает пространство имен, под которым будет расположен сгенерированный код. По умолчанию пространство имен не указывается.ignorecase– указывает, что всю спецификацию следует обрабатывать без учета регистра, если на одном из правил не указаноignoreCase=false.noshared– указывает, что общий код зависимостей не должен быть сгенерирован. По умолчанию Rolex генерирует весь код зависимостей как часть файла сгенерированного токенизатора. Если вы генерируете несколько токенизаторов, вам нужна только одна копия общего кода, поэтому просто укажите параметрnosharedдля второго и следующих токенизаторов, чтобы избежать ошибок компиляции из-за дублирования кода.externaltoken– указывает, что Rolex должен использовать предоставленный токен в указанном пространстве имен вместо генерации своего собственного. Некоторые парсеры предоставляют свою собственную структуру токена. По умолчанию генерируется собственная структураToken.ifstale– указывает, что генерация не должна происходить, если файлoutputfileстарше файлаinputfile. Это может быть полезно как часть предварительного шага сборки, чтобы код не перестраивался, если входные данные не изменились. Это особенно полезно для сложных спецификаций лексера, которые требуют много времени для генерации.nfagraph– генерирует граф конечного автомата NFA для лексера. В основном используется для отладки выражений.dfagraph– генерирует граф конечного автомата DFA для лексера.graph– генерирует граф каждого правила, включая блоки окончаний. Может быть довольно большим по размеру.dpi– DPI сгенерированных графиков – по умолчанию 300.
Спецификация лексера Rolex
Спецификация лексера была разработана в основном для автоматической генерации другими инструментами, например, с помощью Parsley. Однако, она достаточно проста для использования вручную, если вы не боитесь регулярных выражений.
Это формат, основанный на строках, где каждая строка формируется следующим образом:
идентификатор<id=1,ignoreCase>= '[A-Z_][0-9A-Z_]*'
Или более общий вид:
идентификатор [ "<" атрибуты ">" ] "=" ( "'" регулярное выражение "'" | "\"" литерал "\"" )
Каждый атрибут – это идентификатор, за которым может следовать (необязательно) знак равенства и строка, логическое или целочисленное значение в стиле JSON. Если значение не указано, оно принимается равным true, что означает, что параметр ignoreCase установлен в true. Обратите внимание, что литеральные выражения заключаются в двойные кавычки, а регулярные выражения – в одинарные кавычки.
Есть несколько доступных атрибутов, перечисленных ниже:
id– указывает неотрицательный целочисленный идентификатор, связанный с этим символомignoreCase– указывает, что выражение должно интерпретироваться без учета регистраhidden– указывает, что этот символ должен быть проигнорирован лексером и не сообщаться дальшеblockEnd– указывает многозначное условие окончания для указанного символа. При обнаружении лексер будет продолжать чтение до тех пор, пока встретит значениеblockEnd, и потребует его. Это полезно для выражений с множеством условий окончания, таких как комментарии на языке C, комментарии HTML/SGML и секции CDATA XML. Это может быть как регулярное выражение (в одинарных кавычках), так и литерал (в двойных кавычках).
Правила могут быть несколько неоднозначными в том, что они соответствуют. Если они такие, то играет роль первое правило в спецификации, с которым совпадает, и результатом будет набор правил с приоритетом по id (сначала наименьшие) и в противном случае – по порядку в документе.
Язык регулярных выражений поддерживает базовые необратимые конструкции и общие классы символов, а также [: Буква:]/[: БукваИлиЦифра:]/[: Пробел:]/и т.д., которые соответствуют их .NET аналогам. Убедитесь, что экранировали одиночные кавычки, поскольку они используются в Rolex для ограничения выражений.
Сгенерированный API-код
Rolex предоставляет доступ к сгенерированным токенизаторам с помощью простого API. Каждый токенизатор представляет собой класс, в котором каждый символ объявлен как константа целого числа. Токенизатор при создании принимает IEnumerator<char>, который обычно является строкой, но может быть массивом char[] или некоторым другим пользовательским источником, который вы реализуете. В качестве альтернативы можно использовать TextReader. Класс токенизатора поддерживает перечисление foreach по токенам, информация о которых возвращается с помощью структуры Token. Структура Token, в свою очередь, возвращает информацию о строке, столбце, позиции, символе и захвате в свойствах Line, Column, Position, SymbolId и Value соответственно. Свойство TabWidth класса токенизатора позволяет задать ширину табуляции входного устройства. По умолчанию эта ширина равна 4, на случай, если она отличается от этого значения. Это позволяет точно указывать столбцы в случае работы с нестандартными устройствами. Надеюсь, вы можете оставить это свойство без изменений. Обратите внимание, что столбец и позиция – это не одно и то же! Позиция представляет собой индекс кодовой точки UTF-32 в вашем вводе. Если вы передали строку в токенизатор, то Token.Position, приведенный к типу int, не обязательно будет абсолютным индексом в строке. Это связано с тем, что некоторым символам требуются суррогаты для их представления. Чтобы получить индекс символа, используйте Token.AbsoluteIndex. Свойство Column, с другой стороны, начинается с 1 и указывает позицию в макете входного устройства. Это включает учет табуляций, переводов строк и возвратов каретки.
Давайте объединим все, что мы рассмотрели, чтобы начать разбор. Сначала создадим файл спецификаций, Example.rl:
id='[A-Z_a-z][0-9A-Z_a-z]*'int='0|\-?[1-9][0-9]*'space<hidden>='[\r\n\t\v\f ]'lineComment<hidden>= '\/\/[^\n]*'blockComment<hidden,blockEnd="*/">= "/*"
Выше мы определили id и int, а остальные скрытые символы – это пробелы и комментарии.
Теперь нам нужно “достать” из Rolex некоторый код для этого:
Rolex.exe Example.rl /output ExampleTokenizer.cs /namespace RolexDemo
После того, как мы добавим ExampleTokenizer.cs в наш проект, мы можем использовать его следующим образом:
var input = "foo bar/* foobar */ bar 123 baz -345 fubar 1foo *#( 0";
var tokenizer = new ExampleTokenizer(input);
foreach(var tok in tokenizer){
Console.WriteLine("{0}: {1} at column {2}", tok.SymbolId, tok.Value,tok.Column);
}
Что выведет в консоль:
0: foo at column 1 0: bar at column 5 0: bar at column 16 1: 123 at column 20 0: baz at column 24 1: -345 at column 28 0: fubar at column 34 1: 1 at column 41 0: foo at column 45 -1: * at column 49 -1: # at column 51 -1: ( at column 52 1: 0 at column 54
Основной алгоритм, который делает это работу, на самом деле очень простой. Это алгоритм на основе ДКА, созданный с использованием стандартной техники конструкции множества подмножеств, измененной для использования диапазонов символов, а не работы с ними одним за другим, чтобы обрабатывать Юникод. Минимизация основана на алгоритме Хопкрофта (раньше основывалась на алгоритме Хаффмана). Раньше у меня уже было все, кроме этой техники конмножества с использованием диапазонов, но она не работала с Юникодом. Я раньше думал, что это невозможно сделать, пока не увидел, что некоторые другие библиотеки, такие как “brics” на Java и его перенос на C# “Fare”, используют эту технику, но их реализации мне не подходили, потому что наш код слишком сильно отличался. Но я, наконец, разобрался сам. Я подключил уведомление об авторском праве в одном файле, которое затрагивает. В конце концов, это сделано. Я рассматривал использование Fare в Rolex, но исследовав его, я понял, что он совсем не обрабатывает суррогатные символы Юникода, и обработка ошибок была плохой, даже по моим расслабленным стандартам, поэтому я продолжил со своей собственной реализацией. Возможно, Fare работает немного быстрее для больших автоматов, и я знаю, что он существенно быстрее, когда речь идет о работе с большими наборами символов, но он обманывает и не работает с суррогатными значениями. Внутренне в регулярном выражении Rolex используется кодировка UTF-32, поэтому у него нет этой проблемы, но генерация таблиц занимает больше времени в результате этого.
В любом случае, проблема решена. Мои более привлекательные решения, такие как Lexly, мой лексер, основанный на Pike VM, не могут сравниться с хорошей старой DFA в плане производительности, несмотря на все оптимизации, которые я делаю. ДФА не являются крутыми технологиями. Они не небольшие интерпретаторы байткода и так далее. Они скучны, в основном. Но они делают свою работу быстро, и в этом заключается суть.
Как я уже упоминал, основным недостатком, помимо более длительного времени генерации кода, является то, что они не могут легко поддерживать сложные конструкции, такие как якоря, ленивое сопоставление или захватывающие группы без “взлома” алгоритма ДФА. Для токенизаторов эти функции не имеют значения. Ленивое сопоставление может быть важно, но Rolex предлагает альтернативу.
Это компромисс стоит своей скорости. Rolex может проводить лексический анализ примерно в 10 раз быстрее, чем лексер Lexly на базе NFA, и примерно в два раза быстрее, чем лексер Lexly на базе настроенного вручную DFA, просто потому, что он не должен обеспечивать сложную виртуальную машину для выполнения.
Он все еще использует технологию Deslang/Slang для отображения кода, но я отделил его от Build Pack и просто включил инструмент deslang.exe в папку решения для выполнения предварительного шага сборки. Он отвечает за преобразование содержимого папки Export в код Deslanged.cs, который содержит все представления CodeDOM файлов кода в этой папке. Имейте в виду, что файлы в этой папке не являются полноценным C#, а являются подмножеством C#, совместимым с CodeDOM. Если вы их измените, можете что-то сломать, если не знаете, как им пользоваться.
История
- 25 января 2020 года – Первичная отправка
- 4 февраля 2020 года – Исправлена ошибка в FA.Parse()
- 11 февраля 2020 года – Улучшена скорость генерации, исправлена еще одна ошибка в FA.Parse()
- 25 февраля 2020 года – Улучшена скорость генерации, добавлена функция “externaltoken”
- 18 ноября 2023 года – Упрощены таблицы, добавлены параметры, исправлены мелкие ошибки
- 20 ноября 2023 года – Мелкий багфикс, добавлены параметры, улучшена генерация кода





Leave a Reply