Как обрабатывать многоязычные имена в ваших приложениях
Раньше в этом году моя команда на работе и я занимались рассмотрением ошибок, возникающих в одном из наших API для регистрации. Мы заметили, что почти 5% наших запросов завершались неудачно, все из-за ошибок 400 BAD REQUEST [https//developer.mozilla.org/en-US/docs/Web/HTTP/Status/400]. И причиной было обнаружено, что это связано с регулярным выражением.
Ранее в этом году моя рабочая команда и я рассматривали ошибки, возникающие в одном из наших API для регистрации. Мы обнаружили, что почти 5% наших запросов завершаются неудачей из-за ошибок 400 BAD REQUEST. Причиной была проверка регулярного выражения.
Это регулярное выражение было ограничением, поскольку наша система позволяет только использование английских символов для ввода имени и фамилии. Проблема заключалась в том, что многие люди предпочитали вводить свои имена на родном языке.
Эти клиенты были заинтересованы в покупке медицинских полисов на нашей платформе, и они составляли важный сегмент нашей пользовательской базы.
В ответ на это мы решили предоставить этим 5% пользователей возможность вводить имена на любом языке, который им нравится. Но это привнесло много вызовов, которые нам нужно было решить – и я собираюсь объяснить, как мы это сделали.
Проблемы с обработкой многоязыковых имен
1. Стратегия хранения данных
Мы полагаемся на MongoDB для хранения и получения имен пользователей. Хотя MongoDB позволяет хранить все символы, совместимые с UTF-8, проблемы возникают при поиске.
Для английских имен наши операции поиска используют метод simple collation. Соответствующие поля проиндексированы для оптимизации производительности запросов.
Хотя MongoDB также предлагает возможность создания коллационного индекса для других языков, это подразумевает, что вы должны указать БД определенный язык, для которого вы хотите осуществлять поиск. Проблема в том, что наша пользовательская база охватывает множество языков, и только в Индии более 20 различных языков.
Мы стремились поддерживать хотя бы все индийские языки. Но это означало, что реализация коллационных индексов для каждого поддерживаемого языка приведет к увеличению количества индексов и увеличению размера индекса со временем.
Этот подход также предоставляет разработчикам ответственность добавлять индекс для каждого нового языка, поскольку наша поддержка языка расширяется, что далеко не эффективное решение.
2. Ограничение шлюза API
Все наши API доступны через шлюз API. Прежде чем шлюз перенаправляет запрос на соответствующий сервис API, входная политика проверяет статус аутентификации пользователя. После аутентификации пользователь получает основные данные о пользователе, такие как имя, номер телефона и другие метаданные, и добавляет их в заголовок запроса этого API.
Многие API полагаются на эти данные, специфичные для пользователя, в заголовках для дальнейшей обработки.
Но шлюз накладывает ограничение – он разрешает обработку и включение только символов ASCII в заголовки. Поэтому мы должны были убедиться, что даже если имя будет на любом другом языке, ответ, который мы передавали, должен быть исключительно на английском.
Кроме того, этот процесс должен был быть быстрым, так как любая задержка при аутентификации могла привести к замедлению работы API.
3. Проблемы внешних партнеров с местными именами
Даже если мы начали принимать имена на нескольких языках, у нас были партнеры, которые должны были принимать эти имена от нас. Если они не поддерживают многоязыковые имена, путь пользователя будет нарушен.
Один из таких примеров был наш платежный партнер. Мы должны были убедиться, что нашей команде по оплате всегда передается английское имя, даже когда пользователи предоставляют имена на других языках.
Кроме того, мы хотели избежать раздражающих всплывающих окон, которые предлагают пользователям вводить свои имена на английском, когда это возможно. Учитывая эти проблемы, нам нужно было создать работоспособное решение.
Как мы решили эти проблемы
Хотя использование услуги транслитерации от стороннего поставщика могло быть наиболее простым путем, мы решили разработать внутреннее решение, чтобы сократить затраты и иметь полный контроль.
Учитывая шлюз API и требования платежных партнеров, стало ясно, что нам необходимо преобразовывать непроизносимые имена на других языках в английские эквиваленты. Но представление этих английских имен пользователю казалось нелогичным – например, вводить имя на хинди и видеть его преобразованным на английский при входе в аккаунт казалось противоречием.
Для решения этой проблемы мы разработали двойную стратегию именования. Оригинальные поля "firstName" и "lastName" сохраняют имена, введенные пользователем на их языке. Затем мы ввели два дополнительных поля "englishFirstName" и "englishLastName", предназначенные для хранения английских вариантов этих имен. Эти английские имена могут быть переданы шлюзу API и нашим платежным партнерам.
Вернувшись к проблеме эффективного хранения этих имен, мы предполагали, что управление коллационными индексами с увеличением числа поддерживаемых языков станет неподъемной задачей. Также для поиска потребуется указание коллации для каждого запроса, что создает дополнительный уровень сложности. Поэтому мы решили отойти от этого подхода.
Наш подход основан на использовании Unicode. Мы стремились поддерживать несколько языков без ограничений, и осознали, что Unicode может эффективно представлять символы на практически любом языке. Поэтому мы решили хранить Unicode-представления имени и фамилии в соответствующих полях нашей MongoDB.
Мы просто добавили еще один слой между нашей базой данных и приложением. Он преобразует эти Unicode-строки в исходные значения на локальном языке при получении имен из базы данных и преобразовывает локальные имена в соответствующие английские имена. Затем он сохраняет их в полях englishFirstName и englishLastName при выполнении операции вставки или обновления.
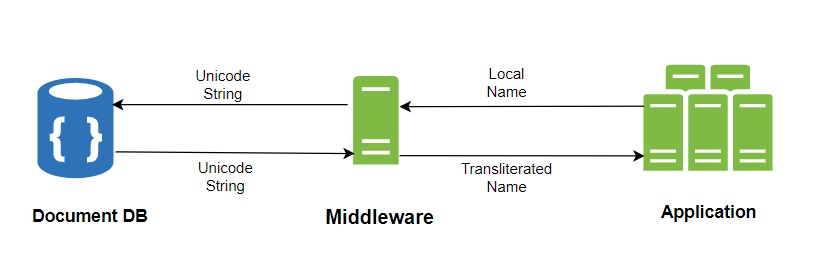
Эта стратегия обеспечила необходимую нам гибкость в управлении многоязычными именами.
Основные аспекты дизайна
1. Оптимизация Unicode
Обычно представление в Unicode состоит из строки из 6 символов, где символ ‘a’ представлен как ‘U+0061’, а символ ‘P’ как ‘U+0050’, обычно начинающаяся с ‘U+00’. Чтобы экономить место в хранилище нашей базы данных, мы решили опустить префикс ‘U+’ и ведущие нули, оптимизируя наше хранилище данных.
2. Транслитерация против перевода
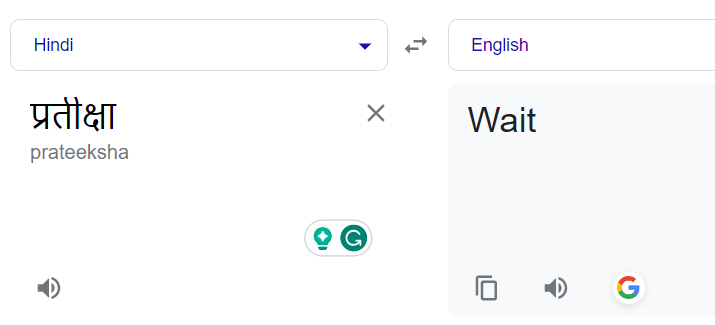
Изначально нашей целью была транслитерация, которая требует преобразования имен из одного алфавита в другой, сохраняя их фонетическое звучание. Например, слово на хинди "प्रतीक्षा" должно быть трансформировано в "Partiksha", а не переведено на его английский эквивалент "Wait".
Но мы осознали, что Google Translate в основном сосредоточен на переводе, а не на транслитерации. Опять же, мы не хотели сразу обращаться к платной услуге Google транслитерации нашей первой версии, поэтому мы разработали нашу службу транслитерации, используя бесплатную версию Google Translate.
3. Контекстные улучшения
Еще одно и наиболее важное наблюдение, которое мы сделали, заключалось в том, чтобы предоставить контекст для API Google Translate, влияющий на его ответы.
Для этого мы экспериментировали с добавлением префиксов к неанглийским именам, чтобы установить контекст. После нескольких попыток мы поняли, что для более коротких имен (менее 5 символов) более обширные предложения-префиксы не давали желаемых результатов, и Google часто возвращал ту же самую слово на хинди. Для длинных имен мы использовали более длинные выражения, определенные оптимальным балансом через пробу и ошибку.
Обычный перевод имен приводил к их буквальному переводу. Например, “प्रतीक्षा” становилось “Wait” вместо “Pratiksha”:
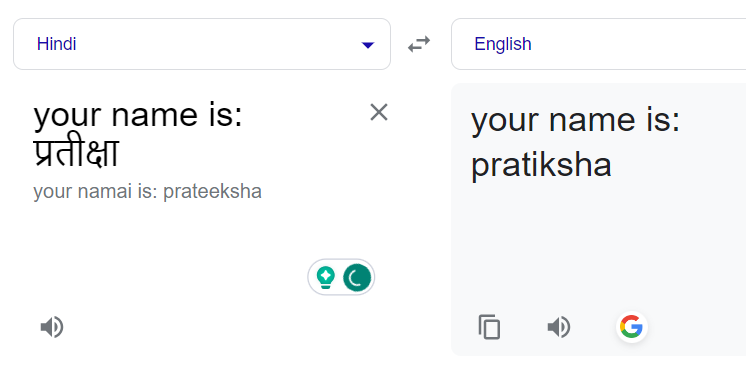
Добавление выражения-префикса исправляет это:
Хорошо, теперь давайте посмотрим, как мы реально реализовали всё это.
Начальный код
После нашей первой итерации мы разработали следующий код для транслитерации. Здесь мы используем библиотеку @iamtraction/google-translate, которая является оберткой над бесплатным API Google Translate.
const translate = require('@iamtraction/google-translate');function getGoogleTranslateText(localName) { /* Добавление английского предложения перед именем, чтобы оно не переводилось на его буквальное значение. Например, Парикша превращается в Exam вместо Pariksha. */ if (localName.length <= 5) { return `имя: ${localName}`; } return `ваше имя: ${localName}`;}async function translateNameToEnglish(localName) { if (localName.match(/^[a-zA-Z ]+$/i)) { // Если имя уже на английском, просто вернуть его return localName; } try { const res = await translate(getGoogleTranslateText(localName), { to: 'en', }); const translatedName = res.text.split(':')[1].trim(); return translatedName; } catch (err) {} // В случае ошибки возвращаем Unicode-строку return localName;}Бета-версия и проблемы на производстве
После создания функции мы выпустили ее в бета-версии, и примерно 250 пользователей зарегистрировались с неправильными именами на нелатинском алфавите в первые несколько дней.
После простого просмотра некоторых переведенных текстов мы обнаружили, что процесс преобразования имени на локальном языке в Юникод работал именно так, как нам нужно, и пользователи могли правильно видеть свои имена на выбранном ими языке.
Тем не менее, мы выявили две проблемы, касающиеся процесса транслитерации на английский язык:
- Некорректная транслитерация имен. Это могло произойти из-за нашей зависимости от Google Translate, общего сервиса перевода, вместо специализированного сервиса транслитерации.
- Некоторые имена оставались неизменными и не транслитерировались. Эти имена возвращались на том же языке, что и оригинальное имя. Проблемы возникали из-за добавления контекста с предложениями перед переводом для конкретных имен.
Это побудило нас провести дальнейшее исследование, которое привело нас к другому npm-пакету под названием “unidecode”, который преобразует Юникод в исходную строку. В ходе начальных тестов с unidecode были обнаружены незначительные орфографические различия. В отличие от этого, Google всегда предоставлял переводы с правильным написанием. Нам просто нужно было найти способ использовать лучшее из двух миров.
Так что мы включили unidecode в наш алгоритм как часть нашего решения.
Улучшенное решение
Вот что мы разработали:
const translate = require('@iamtraction/google-translate');const unidecode = require('unidecode');const { isAlmostEqualStrings } = require('./levenshtein');/** * * @param {String} localName * @description Генерирует текст для Google (контекст для коротких имен) на основе длины localName * @returns {String} возвращает текст для перевода */function getGoogleTranslateText(localName) { /* Добавляем английское предложение перед именем, чтобы оно не переводилось буквально. Например, परीक्षा в Exam, а не Pariksha. */ if (localName.length <= 5) { return `name: ${localName}`; } return `your name is: ${localName}`;}/** * * @param {String} localName * @description Возвращает ПРИБЛИЗИТЕЛЬНО транслитерированное имя * @returns {String} возвращает преобразованное имя на транслитерации из локального языка */function transliterate(localName, googleTranslatedName) { const decodedName = unidecode(localName); if ( decodedName && Array.from(decodedName)[0]?.toLowerCase() !== Array.from(googleTranslatedName)[0]?.toLowerCase() && !isAlmostEqualStrings(decodedName, googleTranslatedName) ) { return decodedName; } return googleTranslatedName;}/** * * @param {String} Input non English string * @description переводит строку с нелатинскими символами на английский язык * @returns {String} возвращает переведенную строку */async function translateNameToEnglish(localName) { if (!localName || localName.match(/^[a-zA-Z ]+$/i)) { // Если имя уже на английском, просто возвращаем его return localName; } try { const res = await translate(getGoogleTranslateText(localName), { to: 'en', }); const translatedName = res.text.split(':')[1].trim(); return transliterate(localName, translatedName); } catch (err) {} // В случае ошибки возвращаем исходную строку return localName;}После получения переведенного имени мы используем его в только что введенной функции transliterate. Внутри этой функции наш первый шаг – извлечь декодированную строку с помощью библиотеки Unidecode. Но затем возникает основная проблема: как мы определяем, какой результат приоритетнее – декодированная строка или переведенная строка?
Для решения этой проблемы мы реализовали расстояние Левенштейна, алгоритм, который вычисляет сходство между двумя строками.
Сначала мы проверяем, совпадает ли первый символ декодированного имени с первым символом переведенного имени. Если нет совпадения, то, несомненно, переведенное имя неверно, поэтому мы возвращаем декодированное имя, хотя оно может содержать незначительные орфографические различия, все равно лучше использовать его, чем неправильный перевод.
Если есть совпадение, мы применяем алгоритм расстояния Левенштейна.
Расстояние Левенштейна – это число, которое показывает, насколько две строки схожи. Чем больше число, тем более различны две строки.
В реализации мы используем функцию isAlmostEqualStrings, которая генерирует значение от 0 до 1 и возвращает true, если значение превышает определенный порог. В нашем случае мы устанавливаем порог равным 0.8
Если расстояние Левенштейна указывает на соответствие более 80%, мы возвращаем переведенное имя. В противном случае мы возвращаем декодированное имя. Такой подход обеспечивает приоритет точности и предлагает надежный результат, основанный на установленном пороге схожести.
Этот обновленный алгоритм значительно снизил вышеупомянутые проблемы. Несмотря на то, что он не является 100% точным, он хорошо решает наши 5% случаев.
Заключение
Разработанный нами алгоритм был полностью внутренним и не повлек за собой затрат. Хотя вложение в платное решение, вероятно, могло бы предложить лучшие результаты, мудрые инженерные решения, принимаемые итеративно, и несколько умных хаков сыграли важную роль как в сокращении затрат, так и в эффективном решении конкретной проблемы, с которой мы столкнулись.
Полный код для вышеуказанной реализации вместе с алгоритмом расстояния Левенштейна можно найти на GitHub (приветствуются вклады/исправления).
С этим мы подходим к концу статьи. Мои сообщения всегда открыты, если вы хотите обсудить что-либо еще на техническую тему или у вас есть вопросы, предложения или обратная связь в целом:
Счастливого обучения!

Leave a Reply