Реализация простого сборщика мусора на C#
Как реализовать простой сборщик мусора на C#?
Введение
Сборка мусора – это процесс в программировании и управлении памятью, в котором система автоматически идентифицирует и освобождает память, которая больше не используется программой. Основная цель сборки мусора заключается в освобождении памяти, занятой объектами или структурами данных, которые больше не достижимы или не используются программой. Это позволяет предотвратить утечки памяти и улучшить эффективность использования памяти.
Мы погрузимся в основные принципы и преимущества этой парадигмы и просто реализуем (на C#) теоретические концепции, которые мы обсуждаем, получая представление о ограничениях каждого концепта. В конечном итоге, мы стремимся разработать полное понимание того, как работает сборка мусора в современных языках программирования.
Авторитетный учебник по этой теме – The Garbage Collection Handbook, опубликованный в 2023 году. Эта книга воплощает богатство знаний, накопленных исследователями и разработчиками в области автоматического управления памятью за последние шестьдесят лет.
Что такое сборка мусора на самом деле?
Как было сказано во введении, сборка мусора – это процесс в программировании и управлении памятью, где система автоматически идентифицирует и освобождает память, которая больше не используется программой.
Ключевые понятия сборки мусора
-
Сборка мусора автоматизирует процесс деаллокации памяти, исключая необходимость вручную управлять памятью программистам. Это помогает предотвратить такие распространенные проблемы, как утечки памяти и висячие указатели (см. ниже).
-
Объекты считаются достижимыми, если на них есть прямые или косвенные ссылки из программы. Сборка мусора идентифицирует и помечает объекты, которые больше не достижимы, делая их пригодными для удаления.
-
Сборщик мусора идентифицирует и освобождает память, занимаемую недоступными объектами, возвращая ее в пул доступной памяти для будущего использования.
-
Сборка мусора может быть инициирована различными событиями, например, когда системе не хватает памяти или при достижении определенного порога выделенной памяти.
Сборка мусора универсально применяется практически во всех современных языках программирования:
- Java использует сборщик мусора виртуальной машины (JVM), который включает различные алгоритмы, такие как генерационный сборщик мусора (G1 GC).
- .NET (C#) реализует сборщик мусора, использующий генерационный подход.
Сборка мусора способствует общей надежности и надежности программ, автоматизируя управление памятью и уменьшая вероятность ошибок, связанных с памятью.
В чем проблема с ручным (явным) управлением памятью?
Ручное управление памятью само по себе не проблематично и все еще используется в некоторых ведущих языках программирования, таких как C++. Однако многие знакомы с случаями критических ошибок, связанных с утечкой памяти. Вот почему, относительно рано в истории компьютерных наук (с самой первой техникой, уходящей в 1950-е годы), были исследованы методы для автоматического управления памятью.
Ручное управление памятью действительно создает несколько вызовов и потенциальных проблем:
-
Неправильная деаллокация памяти может привести к утечкам памяти. Утечки памяти происходят, когда программа выделяет память, но не освобождает ее, что приводит к постепенному истощению доступной памяти со временем.
-
Неправильная работа с указателями может привести к висячим указателям, указывающим на области памяти, которые были деаллоцированы. Обращение к таким указателям может привести к неопределенному поведению и сбоям приложения.
-
Некорректное управление памятью, такое как запись за пределы выделенной памяти, может вызвать повреждение памяти. Повреждение памяти может привести к непредвиденному поведению, сбоям или уязвимостям безопасности.
-
Ручное управление памятью увеличивает сложность кода, делая программы более подверженными ошибкам и труднодоступными для обслуживания. Разработчикам необходимо внимательно отслеживать и управлять выделением и освобождением памяти во всей кодовой базе.
-
Ручное управление памятью может способствовать фрагментации памяти, когда свободная память разбросана в маленьких, несмежных блоках. Эта фрагментация может привести к неэффективному использованию памяти со временем.
-
Может возникнуть несоответствие между операциями выделения и освобождения памяти, что приводит к ошибкам, таким как двойное освобождение или утечки памяти. Эти ошибки сложно идентифицировать и устранять.
-
Явное управление памятью может потребовать дополнительного кода для выделения и освобождения, что влияет на производительность программы. Операции выделения и освобождения памяти могут стать узким местом в приложениях, где требуется высокая производительность.
-
Ручное управление памятью не имеет функций безопасности, присутствующих в системах автоматического управления памятью. Разработчики должны внимательно обрабатывать операции, связанные с памятью, что делает программы более подверженными ошибкам.
Автоматическое управление памятью решает эти проблемы путем автоматизации процесса выделения и освобождения памяти, снижая нагрузку на разработчиков и минимизируя вероятность возникновения ошибок, связанных с памятью.
Более полное описание преимуществ сборки мусора и недостатков явного управления памятью приведено в “Руководстве сборщика мусора”.
Что такое стеки, кучи и многое другое?
При обсуждении сборки мусора часто упоминаются такие термины, как стек и куча, до такой степени, что может создаться впечатление, что они являются врожденными структурами данных, встроенными в операционную систему и, следовательно, должны быть всеобще принятыми без вопросов. Однако реальность состоит в том, что куча и стеки – это всего лишь детали реализации. В этом разделе мы затронем и проясним все эти концепции.
В начале было Слово
Программа в основном представляет собой текст, состоящий из инструкций, которые компьютер должен понять. Ответственность компилятора заключается в том, чтобы выполнить перевод этих инструкций высокого уровня в исполнимый код.
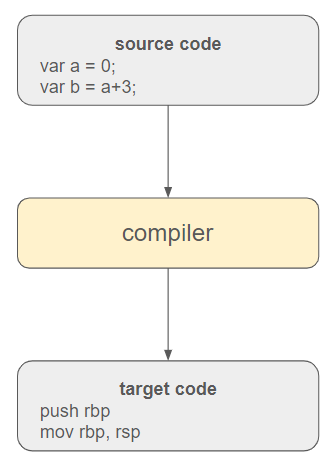
В современных языках программирования между исходным кодом и операционной системой часто встраивается виртуальный исполнительный движок. Кроме того, исходный код изначально переводится на промежуточный язык, чтобы обеспечить переносимость и адаптивность к различным средам.
Этот исполнительный движок включает в себя сборщик мусора и другие техники (такие как типизация, управление исключениями и т. д.) для управления программой. Окончательное преобразование в целевой код выполняется компилятором JIT (just-in-time).
Фокус на сборщике мусора
Безусловно, сборщик мусора является одной из наиболее важных компонентов исполнительного движка. В этом контексте мы сосредоточимся на описании того, как память организована для обеспечения эффективного управления.
Программа становится ценной только тогда, когда она генерирует результат, и неизбежно нуждается в объявлении переменных и выделении памяти для хранения информации.
- Исполнительный движок может заранее предвидеть необходимое пространство, например, при работе с простыми типами, такими как целые числа. Как правило, определение места хранения переменных и выделение памяти в этом случае происходит только во время выполнения (динамическое выделение). Если компилятор может определить время жизни переменной, особенно если она локальна для процедуры, становится проще понять, когда переменная больше не понадобится (т.е. когда может произойти освобождение). В отличие от этого, данные могут сохраняться после вызова функции или подпрограммы и существовать бесконечно.
- Разность между временем жизни переменной и объемом памяти, который известен заранее, требует разграничения между двумя областями памяти. Хотя данное различие не является обязательным, оно стало всеобщим принятием и реализовано. Язык программирования, отказывающийся принять эту абстракцию, может столкнуться с риском устаревания, но важно понимать, что возможны альтернативные схемы. Кроме того, важно отметить, что эта перспектива является валидной только в контексте исполнительного движка. С точки зрения операционной системы все в конечном итоге сводится к выделенным где-то блокам памяти.
Вывод
- Когда исполнительный движок может предвидеть время жизни переменной и выделить нужное пространство, он выделяет его во внутренней области памяти, называемой стеком.
- В других случаях, когда время жизни нельзя однозначно определить или нужное пространство неясно, исполнительный движок выделяет переменные в областях памяти, называемых кучей.
Отказ от ответственности: Это описание предоставляет только базовый обзор стеков и куч в различных языках программирования, и пуристы могут считать его упрощенным. Это не является официальным определением, поскольку возможны различные реализации и интерпретации этих абстракций. Важно понять необходимость разграничения двух областей памяти на уровне исполнительного движка для обеспечения эффективного управления памятью.
Достаточно теории, покажите код, пожалуйста!
Представим себе ситуацию, когда программа сначала написана в исходном коде, а затем компилируется в промежуточное представление, выраженное в виде последовательного списка инструкций. Мы предположим, что компилятор IL сгенерировал этот список инструкций. Пример такого списка приведен ниже.
thread1;CREATE_THREAD; thread1;PUSH_ON_STACK;Jubilant thread2;CREATE_THREAD; thread1;PUSH_ON_STACK;Radiant thread1;POP_FROM_STACK...
Каждая инструкция состоит из трех компонентов. Первый указывает, какой поток затронут инструкцией, второй описывает операцию, которую нужно выполнить, а третий (необязательный) предоставляет значение для дополнения операции. В предоставленном примере компилятору сначала указывается создать поток с именем thread1, затем поместить переменную с именем Jubilant на стек этого потока. В третьей инструкции требуется создать еще один поток с именем thread2 и так далее. Пятая инструкция предполагает выталкивание стека потока thread1.
Этот список инструкций можно представить как промежуточное представление (IR), как показано в книге “Компиляторы: принципы, техники и инструменты”.
Наша текущая задача – реализовать исполнительный модуль (распределение времени выполнения), способный обрабатывать эти инструкции, особенно с акцентом на выделение и освобождение памяти.
Реализация Распределения Времени
Без лишних задержек представим, как реализовано распределение времени в нашем коде.
public class Runtime{ private List<Instruction> _instructions; private Collectors.Interfaces.GarbageCollector _collector; public Runtime(List<Instruction> instructions, string collectorStrategy) { _instructions = instructions; _collector = GetCollector(collectorStrategy); } #region Public Methods public void Run() { foreach (var instruction in _instructions) { _collector.ExecuteInstruction(instruction); _collector.PrintMemory(); } } #endregion}
Модуль исполнения содержит список инструкций для выполнения и коллектор мусора (описанный ниже), который будет использоваться при освобождении памяти. Он также включает метод Run, вызываемый главным потоком.
public class Program{ static void Main(string[] args) { var instructions = new List<Instruction>(); var contents = File.ReadAllLines(AppContext.BaseDirectory + "/instructions.txt"); foreach (var line in contents) { var c = line.Split(';'); var intruction = new Instruction(c[0], c[1], c[2]); instructions.Add(intruction); } var runtime = new Runtime(instructions, "MARK_AND_COMPACT"); runtime.Run(); }}
Класс Runtime также требует стратегию сборки мусора для применения. Как мы увидим, есть несколько возможностей сборки мусора, и создание эффективного сборщика мусора действительно изящное искусство.
Определение интерфейса Collector мусора
Классу Runtime требуется экземпляр класса GarbageCollection для работы. Этот экземпляр реализует абстрактный класс GarbageCollection, методы которого подробно описаны ниже:
public abstract class GarbageCollector{ public abstract void ExecuteInstruction(Instruction instruction); public abstract int Allocate(string field); public abstract void Collect(); public abstract void PrintMemory(); }
По сути, класс GarbageCollector, представленный здесь, служит оркестратором для выполнения списка инструкций и управления выделением и сборкой памяти. В реальных реализациях эти абстракции обычно содержатся отдельно, но в данном случае цель состоит в упрощении представления.
Метод PrintMemory представляет собой вспомогательную функцию, предназначенную для отображения содержимого кучи во время отладки.
Определение Потока
Поток означает самую маленькую единицу выполнения внутри процесса. Процесс является независимой программой, работающей в своем собственном пространстве памяти, и внутри процесса могут существовать несколько потоков. Каждый поток разделяет одни и те же ресурсы, такие как память, с другими потоками в том же процессе.
- Потоки позволяют параллельное выполнение задач, позволяя выполнять несколько операций одновременно. Они работают независимо, собственным счетчиком команд, регистрами и стеком, но разделяют одно и то же пространство памяти. Потоки внутри одного процесса могут взаимодействовать и синхронизироваться друг с другом.
- Потоки широко применяются в современной разработке программного обеспечения для улучшения производительности, отзывчивости и использования ресурсов в приложениях, начиная от настольных программ до серверных приложений и распределенных систем.
public class RuntimeThread { private Collectors.Interfaces.GarbageCollector _collector; private Stack<RuntimeStackItem> _stack; private Dictionary<int, RuntimeStackItem> _roots; private int _stackSize; private int _index; public string Name { get; set; } public RuntimeThread(Collectors.Interfaces.GarbageCollector collector, int stackSize, string name) { _collector = collector; _stack = new Stack<RuntimeStackItem>(stackSize); _roots = new Dictionary<int, RuntimeStackItem>(); _stackSize = stackSize; _index = 0; Name = name; } public Dictionary<int, RuntimeStackItem> Roots => _roots; public void PushInstruction(string value) { _index++; if (_index > _stackSize) throw new StackOverflowException(); var address = _collector.Allocate(value); var stackItem = new RuntimeStackItem(address); _stack.Push(stackItem); _roots.Add(address, stackItem); } public void PopInstruction() { _index--; var item = _stack.Pop(); _roots.Remove(item.StartIndexInTheHeap); } }
Поток характеризуется именем и выполняет свой собственный список инструкций. Ключевой момент состоит в том, что потоки совместно используют одну и ту же память. Это означает, что в программе может быть несколько потоков и, следовательно, несколько стеков, но обычно есть одна общая куча для всех потоков.
В предоставленном примере, когда поток выполняет инструкцию, она помещается в его стек, а любая возможная ссылка на кучу сохраняется во внутреннем словаре. Этот механизм гарантирует, что каждый поток поддерживает свой собственный стек, в то время как ссылки на общую кучу отслеживаются для эффективного управления выделением и освобождением памяти.
Определение стеков и кучи
Как уже упоминалось ранее, стеки и кучи являются деталями реализации, поэтому их код откладывается на конкретные классы GarbageCollector. Тем не менее, это все равно может быть информативным, чтобы предоставить краткое описание, потому что, как мы уже наблюдали, эти концепции всеобще приняты.
Реализация стека
В C# уже есть структура данных для стеков. Для простоты мы будем использовать ее, особенно так как она отлично подходит для наших требований.
Мы будем помещать экземпляры класса RuntimeStackItem на этот стек. RuntimeStackItem просто содержит ссылку на адрес в куче.
public class RuntimeStackItem{ public int StartIndexInTheHeap { get; set; } public RuntimeStackItem(int startIndexInTheHeap) { StartIndexInTheHeap = startIndexInTheHeap; }}
Реализация кучи
Куча должна представлять область памяти, и мы просто смоделируем каждую ячейку памяти с помощью класса char. С этой абстракцией куча представляет собой не что иное, как список ячеек, которые могут быть выделены. Она также включает дополнительный код для управления указателями, чтобы определить, какие ячейки заняты или могут быть освобождены.
public class RuntimeHeap{ public RuntimeHeap(int size) { Size = size; Cells = new RuntimeHeapCell[size]; Pointers = new List<RuntimeHeapPointer>(); for (var i = 0; i < size; i++) { Cells[i] = new RuntimeHeapCell(); } } #region Properties public int Size { get; set; } public RuntimeHeapCell[] Cells { get; set; } public List<RuntimeHeapPointer> Pointers { get; set; } #endregion}
Теперь наша задача – определить конкретные классы GarbageCollection, чтобы наблюдать за действием мусорного коллектора.
Реализация алгоритма “Mark-and-Sweep”
Для этой стратегии и последующих мы выделяем кучу из 64 символов и считаем невозможным запросить дополнительное пространство у операционной системы. В реальном сценарии мусорный коллектор обычно может запросить новую память, но с целью пояснения мы наложили этот ограничение. Важно отметить, что это ограничение не затрудняет понимание и не снижает его качество.
Реализация метода ExecuteInstruction
Этот метод практически одинаков для всех стратегий. Он обрабатывает по одной инструкции, помещая или извлекая переменные на стеке.
public override void ExecuteInstruction(Instruction instruction){ if (instruction.Operation == "CREATE_THREAD") { AddThread(instruction.Name); return; } var thread = _threads.FirstOrDefault(x => x.Name == instruction.Name); if (thread == null) return; if (instruction.Operation == "PUSH_ON_STACK") { thread.PushInstruction(instruction.Value); } if (instruction.Operation == "POP_FROM_STACK") { thread.PopInstruction(); }}
Реализация метода Allocate
Если памяти недостаточно, мусорный коллектор пытается восстановить память и повторить процесс выделения. Если всё еще не хватает места, генерируется исключение.
public override int Allocate(string field){ var r = AllocateHeap(field); if (r == -1) { Collect(); r = AllocateHeap(field); } if (r == -1) throw new InsufficientMemoryException(); return r;}private int AllocateHeap(string field){ var size = _heap.Size; var cells = field.ToArray(); var requiredSize = cells.Length; // Нам нужно найти непрерывный блок требуемого размера символов. var begin = 0; while (begin < size) { var c = _heap.Cells[begin]; if (c.Cell != '\0') { begin++; continue; } // Не продолжаем, если места не хватает. if ((size - begin) < requiredSize) return -1; // c = 0 => Эта ячейка свободна. var subCells = _heap.Cells.Skip(begin).Take(requiredSize).ToArray(); if (subCells.All(x => x.Cell == '\0')) { for (var i = begin; i < begin + requiredSize; i++) { _heap.Cells[i].Cell = cells[i - begin]; } var pointer = new RuntimeHeapPointer(begin, requiredSize); _heap.Pointers.Add(pointer); return begin; } begin++; } return -1;}
Важно: Процесс выделения памяти всегда ищет непрерывное свободное пространство (строка 23 вышеуказанного исходного кода). Например, если требуется выделить 8 ячеек, необходимо найти 8 свободных смежных ячеек. Это наблюдение окажется ключевым в последующих разделах (см. ниже).
Что такое алгоритм “пометить и освободить”?
Алгоритм “пометить и освободить” состоит из двух основных фаз: пометки и освобождения.
- В фазе пометки алгоритм проходит по всем объектам в куче, начиная с корневых (обычно глобальных переменных или объектов, на которые прямо ссылается программа). Он помечает каждый посещенный объект как “достижимый” или “живой”, установив определенный флаг или атрибут. Непомеченные объекты во время этого прохода считаются недостижимыми и потенциально могут быть освобождены.
- В фазе освобождения алгоритм сканирует всю кучу, идентифицируя и освобождая память, занятую непомеченными (недостижимыми) объектами. Память, занятая помеченными (достижимыми) объектами, сохраняется. После освобождения куча снова считается непрерывным блоком свободной памяти, готовым для новых выделений.
Алгоритм “пометить и освободить” известен своей простотой и эффективностью в определении и освобождении памяти, которая уже не используется. Однако у него есть некоторые недостатки, о которых мы увидим далее.
В итоге объект считается мертвым (и, следовательно, освобождаемым), пока он не докажет обратное, став доступным из программы.
public override void Collect(){ MarkFromRoots(); Sweep();}
Реализация фазы пометки
Алгоритм “пометить и освободить” должен начать свой проход с корней. Что является такими корнями? Обычно это глобальные переменные или ссылки, содержащиеся во фрейме каждого стека. В нашем упрощенном примере мы определим корни как объекты, на которые ссылается стек.
private void MarkFromRoots(){ var pointers = _heap.Pointers; foreach (var root in _threads.SelectMany(x => x.Roots)) { var startIndexInTheHeap = root.Value.StartIndexInTheHeap; var pointer = pointers.FirstOrDefault(x => x.StartCellIndex == startIndexInTheHeap); if (pointer == null) return; pointer.SetMarked(true); }}
По окончании процедуры будут помечены живые объекты, а неживые – нет.
Реализация фазы освобождения
Фаза освобождения сканирует всю кучу и освобождает память от объектов, которые не помечены.
private void Sweep(){ var cells = _heap.Cells; var pointers = _heap.Pointers; foreach (var pointer in pointers.Where(x => !x.IsMarked)) { var address = pointer.StartCellIndex; for (var i = address; i < address + pointer.AllocationSize; i++) { cells[i].Cell = '\0'; } } var list = new List<RuntimeHeapPointer>(); foreach (var pointer in pointers.Where(x => x.IsMarked)) { pointer.SetMarked(false); list.Add(pointer); } pointers = list;}
В этой процедуре мы не забываем снова установить помеченные указатели в непомеченное состояние, чтобы следующая сборка мусора работала с чистым полотном.
Запуск программы
Мы выполним программу с двумя списками инструкций. Первый идентичен тому, который был в предыдущей статье. Второй подчеркнет особенность этого алгоритма, известную как фрагментация.
С тем же набором инструкций, что и ранее, мы видим, что программа работает до конца без возбуждения исключения. Слово “Cascade” было правильно выделено, потому что сборщик мусора сумел освободить достаточно памяти.
Этот алгоритм гарантирует правильное освобождение памяти по мере необходимости. Однако в следующем примере мы увидим нежелательный эффект, когда слегка изменяем наши инструкции и пытаемся выделить память для длинного слова (из 16 букв).
...поток1;ПОМЕСТИТЬ_НА_СТЕК;Загадочныйпоток2;УДАЛИТЬ_СО_СТЕКА;поток1;ПОМЕСТИТЬ_НА_СТЕК;Каскадпоток2;УДАЛИТЬ_СО_СТЕК;поток2;ПОМЕСТИТЬ_НА_СТЕК;СборщикМусора <= слова из 16 букв
Удивительно, хотя на куче кажется, что свободной памяти достаточно, возникает исключение.
В куче имеется 19 свободных ячеек, и мы пытаемся выделить 16 ячеек, почему же сборщик мусора не может выполнить эту задачу?
На самом деле сборщик мусора пытается найти 16 СОСЕДНИХ свободных ячеек, но похоже, что куча их не имеет. Хотя свободных ячеек больше 16, они не являются соседними, что делает выделение невозможным. Это явление известно как фрагментация и имеет некоторые нежелательные последствия.
Более обще говоря, фрагментация кучи относится к ситуации, когда свободная память в куче распределена в несоседних блоках, что затрудняет выделение большого непрерывного блока памяти, даже если общий объем свободного пространства достаточен. В то время как общее количество свободной памяти может быть значительным, неравномерное распределение этих блоков затрудняет выделение больших непрерывных частей памяти.
В контексте алгоритма маркировки и смены фазы, потребность в непрерывных блоках памяти для определенных выделений может быть препятствована неравномерным расположением свободных ячеек памяти в куче. В результате, даже если общее свободное пространство достаточно, невозможность найти достаточно большой непрерывный сегмент может привести к неудачным выделениям.
Таким образом, решение проблемы фрагментации кучи является важным для оптимизации использования памяти и повышения производительности сборщика мусора.
Продолжение статьи вы можете найти здесь.
История
- 18 ноября 2023: Исходная версия





Leave a Reply